
- PagerDuty /
- Engineering Blog /
- Distributed Task Scheduling, Part 2: Handling Dynamic Load
Engineering Blog
Distributed Task Scheduling, Part 2: Handling Dynamic Load
by David Van Geest
August 17, 2017
| 8 min read
In an earlier post, we discussed how PagerDuty has built a distributed task scheduler using Akka, Kafka, and Cassandra. This open-source Scala library schedules and executes some of our critical tasks, despite rapidly changing infrastructure.
In Part 2 of this series, we’ll discuss how Scheduler tackles a challenge common to many systems: how do you handle constantly changing load while ensuring that your tasks still run on time? Questions like this are the reason that many systems are distributed in the first place; distributing your application across a fleet of ephemeral and inexpensive hardware is one way to elastically handle changing load.
At PagerDuty, our traffic can be highly dynamic. For example, when a common AWS component such as S3 has a problem, many of our customers will have a spike in incidents. Likewise, on days such as Black Friday, when consumer web traffic is much higher than normal, our system will need to handle a higher load. An application using Scheduler will need to keep up with this higher volume of traffic, and therefore higher volume of tasks.
An application based on Scheduler may need to scale in different ways: we might be scheduling more tasks, or we might have more tasks being persisted (say, for later execution), or we might find tasks are slower to execute and might need to scale the number of tasks we can execute concurrently. Scheduler enables independent scaling of different components in these different scenarios.
Scaling Kafka
In a situation where the rate of task scheduling is expected to increase, we will need to scale Kafka since scheduling a task just means serializing and publishing it to a Kafka topic. For Scheduler’s typical workload at PagerDuty, Kafka will scale horizontally; that is, we can keep adding brokers to the cluster to deal with increased task throughput.
For a given topic in Kafka (you can think of a topic like a queue in a traditional message broker, although they are considerably different), there are N possibly replicated partitions. These topic partitions are spread evenly across the available brokers such that each broker manages an even share of the traffic, and therefore an even share of the disk IO. Conveniently, Kafka can dynamically rebalance the topic partitions to ensure that the load is still balanced, even when you add or subtract a broker from the cluster.
Let’s take a look at how this works with an example. In this example we have two brokers, and a single topic split into 6 partitions. Each partition is replicated once from a leader to a follower. All reads and writes for a specific topic partition go to the leader for that partition, and, in the case of a write, the leader will forward the write to all of the followers. The following diagram shows this scenario, with each broker being the leader for three partitions and a follower for the other three.

Now let’s say that we start exhausting disk IO on our two brokers, and we need to add a third broker. To make use of this new broker, Kafka allows us to manually initiate an automatic redistribution of the partitions. After the redistribution, each broker is a leader for two partitions, and a follower for two. Each broker now deals with four partitions instead of six, as shown in the diagram, below.

Again we scale out, adding three additional brokers. Each broker is now only a leader for one partition, and a follower for one. This diagram shows the new state of the cluster.
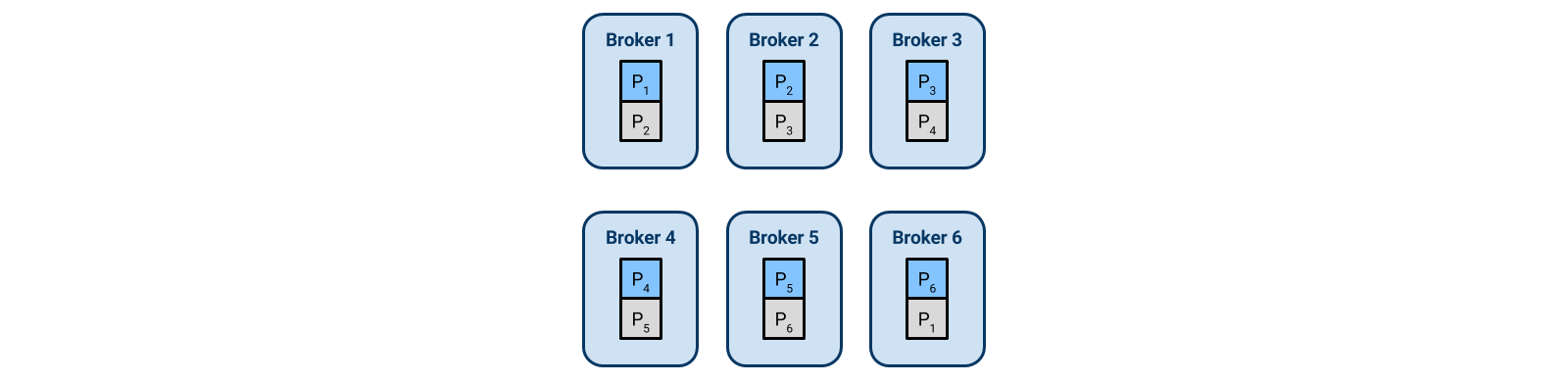
An important thing to note is that for this to continue scaling we should have significantly more partitions than expected brokers. This example is not going to continue scaling further than twelve brokers – at that point each broker is either a leader or a follower for a single partition, and adding additional brokers would have no effect.
Scaling the Service
What happens when there are more tasks to execute, or the tasks begin taking much longer? In this scenario, we need to scale the Scheduler-based service. Again, we can scale the application horizontally; this is actually enabled by Kafka.
The consumers of a given topic, in this case service instances, are grouped together by Kafka in a consumer group. The group’s healthy consumers are tracked by Kafka, and the topic’s partitions are distributed evenly to the healthy consumers. This topic distribution is a dynamic process; if consumers die, or consumers are added, the partitions are automatically re-assigned.
Below is an example with a topic that has five partitions. There are two service instances in the same consumer group, so one service instance is given three partitions and the other is given two.
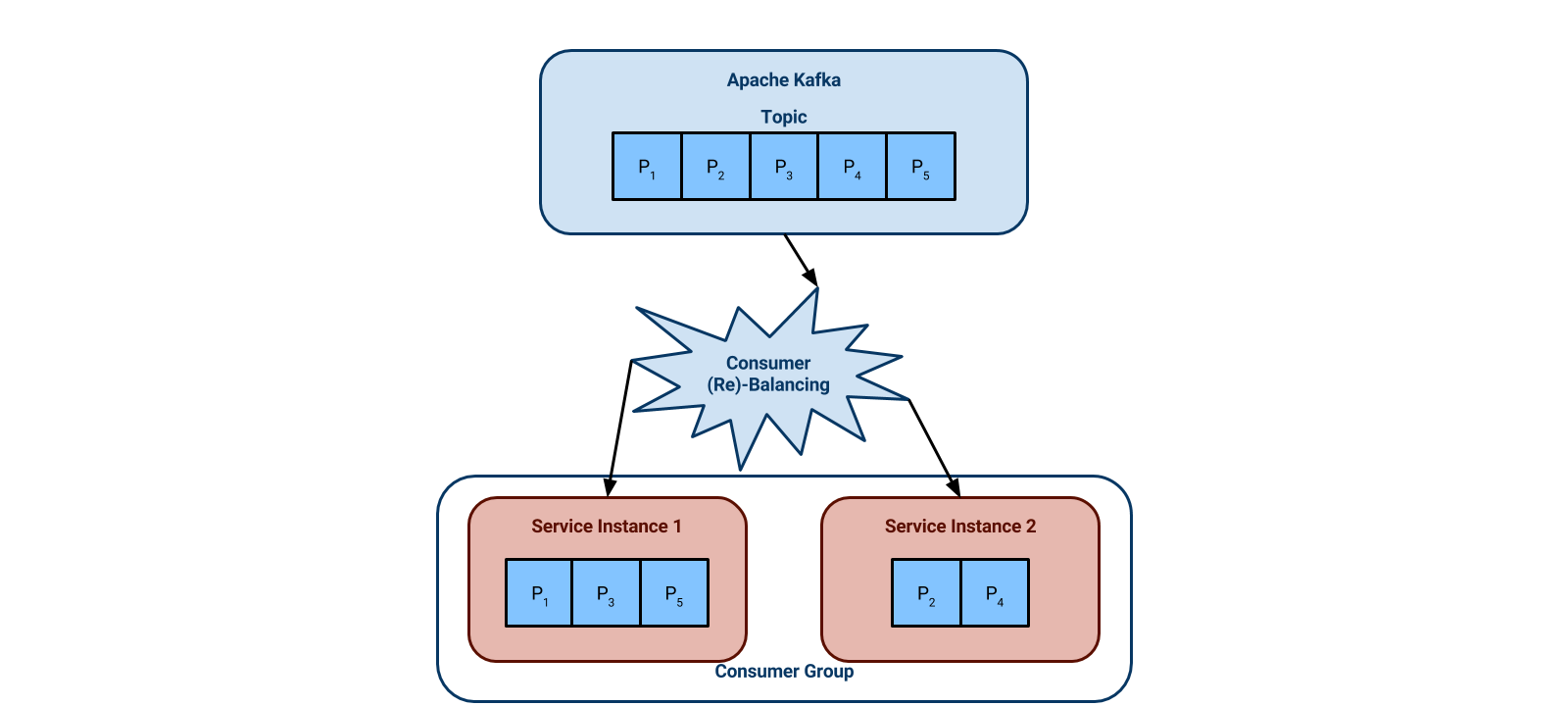
Now let’s say that our two service instances can’t keep up with the workload. The next diagram shows us adding a third instance. Kafka automatically re-assigns the partitions such that they are evenly distributed across the three instances. Each instance is now responsible for two partitions maximum, instead of the previous three. This is called a consumer rebalance.
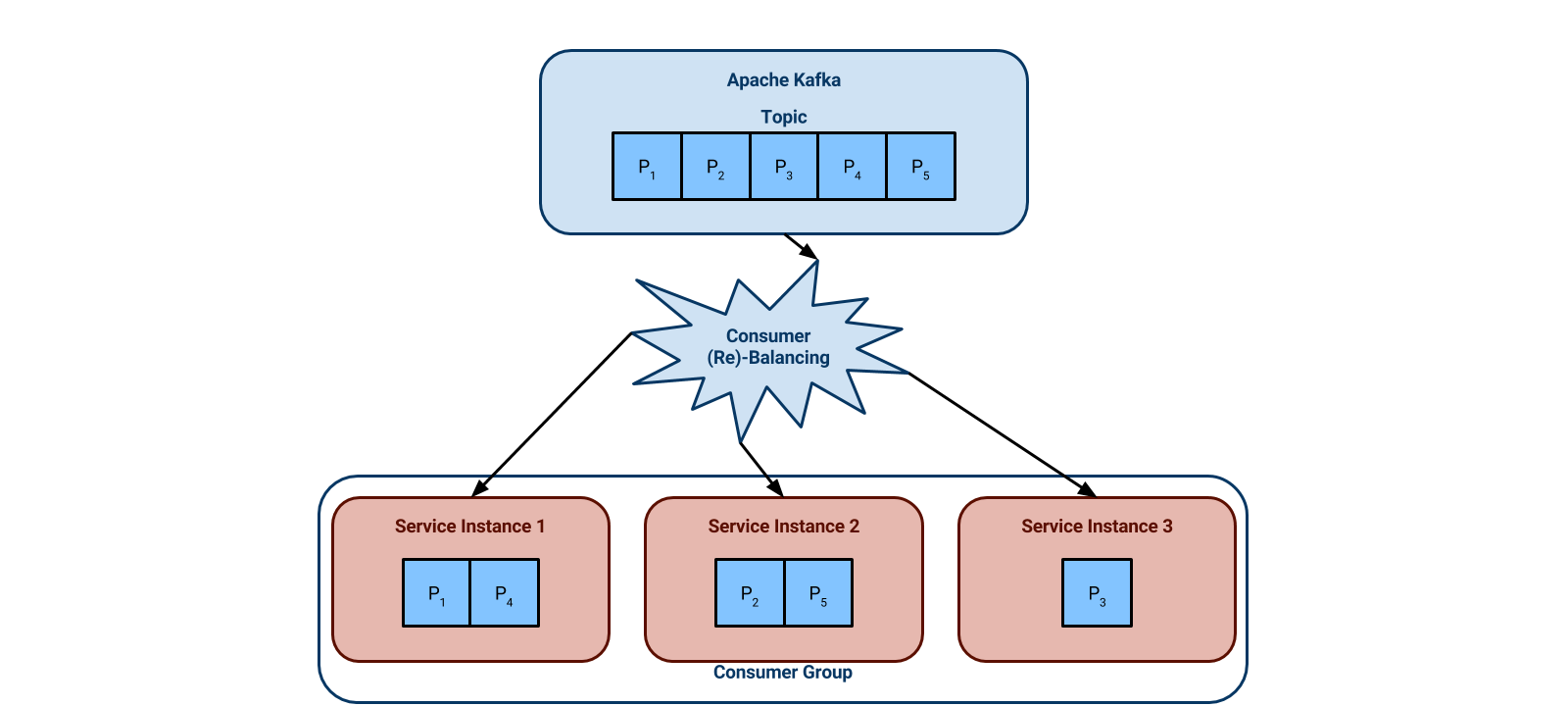
Again, note that this scaling is not effective once the number of instances equals the number of topic partitions; the instances have to work at least one partition. Keep this in mind when choosing the number of partitions for a topic.
Scaling Cassandra
The previous sections showed how we could scale Kafka, and how we could scale the application consuming from Kafka. However, we still need to persist our tasks somewhere. If we have more and more tasks to persist, we must eventually scale our data store.
In Scheduler, Cassandra is used for task persistence, and like Kafka, it will scale horizontally. Managing Cassandra is a large topic that we won’t attempt to tackle thoroughly in this post, but we’ll lay down a few basics.
The key for a Cassandra row is hashed into a token in a known, very large range. The nodes in the cluster are each assigned a range of those tokens; any given row will be persisted onto a known node in the cluster. As you add Cassandra nodes, the original nodes become responsible for an increasingly smaller range of tokens.
In the example diagram below, we have four Cassandra nodes. To make the math easy, we’ll say that the range of tokens is 0 to 99 – in reality the range is much, much larger. This example range is evenly divided into four, with each node being responsible for the previous 25 tokens. For example, Node 1 is responsible for 76 to 0 and Node 2 is responsible for 1 to 25. When we insert a new row into the cluster, Cassandra hashes the row key to obtain a token and that token dictates on which node the row will be persisted. In this example, a new row has a token of 80, so it will live on node 1 (note that this example doesn’t include row replication).
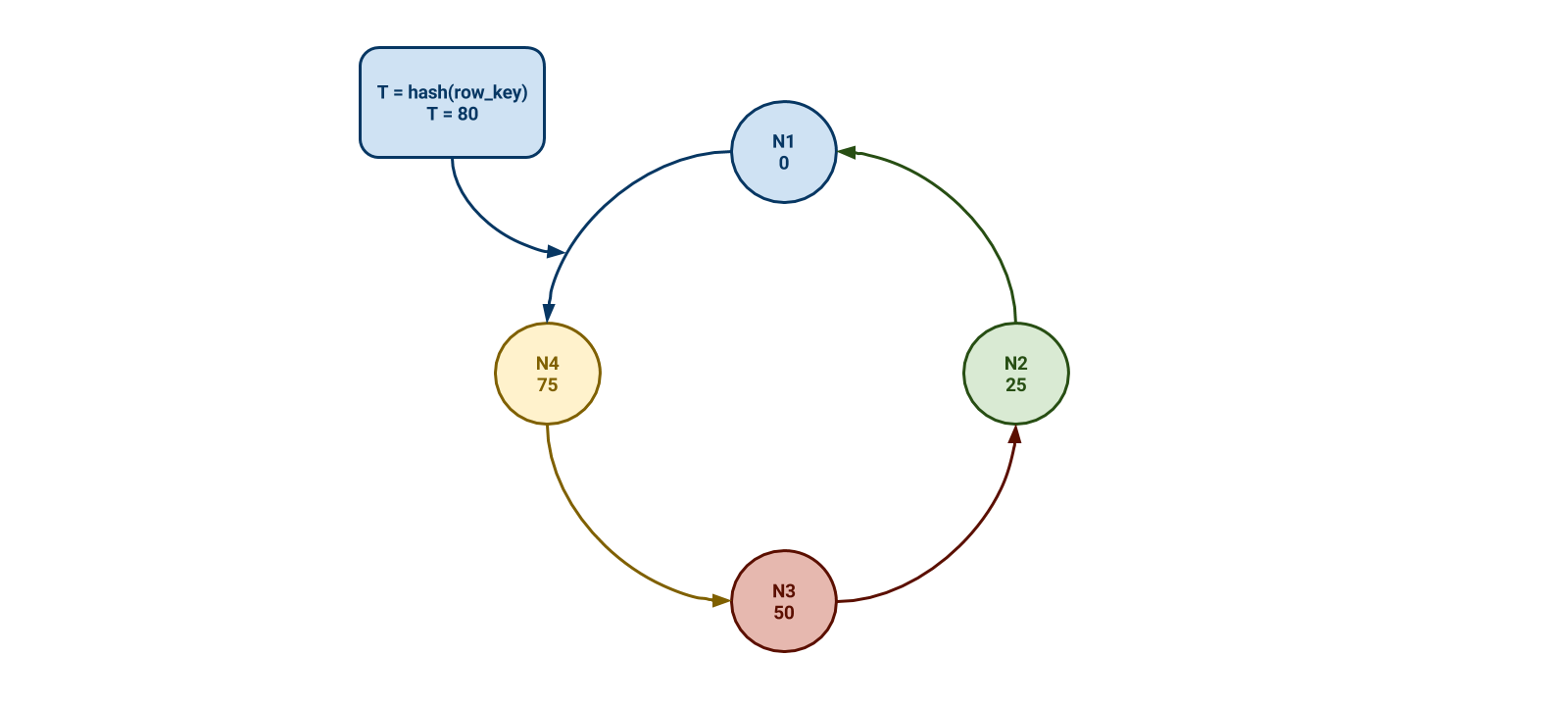
If our four Cassandra nodes are having trouble keeping up, we might add a fifth node to the cluster. We then have to shift the token ranges around such that they are still evenly distributed. In the diagram below, each node is now responsible for 20 tokens instead of 25.
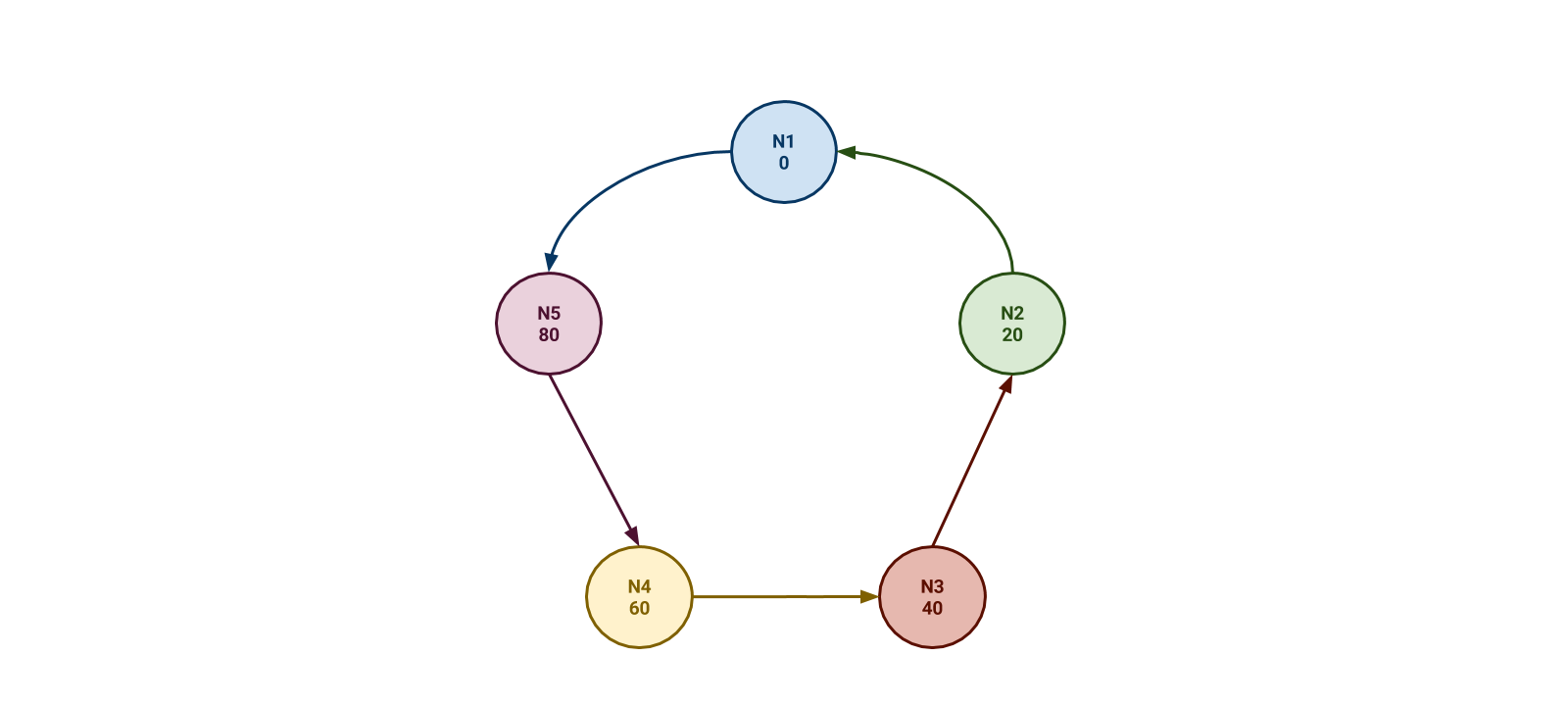
This is a vast over-simplification, and in particular doesn’t take into account Cassandra’s vnode feature (which is extremely helpful), but, hopefully it helps us understand the basic concepts behind Cassandra scaling.
Scaling Scheduler by Scaling its Components
We’ve seen that we can scale an application based on Scheduler in a few different ways. If we are scheduling more tasks, we add Kafka brokers to the cluster and redistribute Scheduler’s topic partitions. If we are persisting more tasks, we can add nodes to our Cassandra cluster to handle the increased load. Finally, if we are executing more tasks, we add more service instances and Kafka’s consumer rebalancing allocates them tasks to work.
These three stages of the Scheduler pipeline generally have correlated scaling characteristics – if we are scheduling more tasks we should also be executing more tasks! But of course Kafka, Cassandra, and our application scale at different rates. Perhaps we can easily schedule more tasks in Kafka but we can’t easily persist that same additional number to Cassandra. The architecture of Scheduler allows us to scale these individual components as required.
Up Next…
We’ve covered a lot of foundational ground in this post, but we’ll build on it in subsequent posts in this series. Next up, look for a post discussing how Scheduler enables an application to handle a data center outage while still running its tasks on-time!
