
- PagerDuty /
- Blog /
- Partnerships /
- A Disunity of Data: The Case For Alerting on What You See
Blog
A Disunity of Data: The Case For Alerting on What You See
by Vivian Au
August 21, 2014
| 6 min read
Guest blog post by Dave Josephsen, developer evangelist at Librato. Librato provides a complete solution for monitoring and understanding the metrics that impact your business at all levels of the stack.
The assumption underlying all monitoring systems is the existence of an entity that we cannot fully control. A thing we have created, like an airplane, or even a thing that simply exists by means of miraculous biology, like the human body. A thing that would be perfect, but for its interaction with the dirty, analog reality of meatspace; the playground of entropy, and chaos where the best engineering we can manage eventually goes sideways through age, human-error, and random happenstance.
Monitor that which you cannot control
Airplanes and bodies are systems. Not only do we expect them to operate in a particular way, but we have well-defined mental models that describe their proper operational characteristics — simple assumptions about how they should work, which map to metrics we can measure that enable us to describe these systems as ‘good’ or ‘bad’. Airplane tires should maintain 60 PSI of pressure, human hearts should beat between 40 and 100 times per minute. The JDBC client shouldn’t ever need more than a pool of 150 DB connections.
This is why we monitor: to obtain closed-loop feedback on the operational characteristics of systems we cannot fully control, to make sure they’re operating within bounds we expect. Fundamentally, monitoring is a signal processing problem, and therefore, all monitoring systems are signal processing systems. Some monitoring systems sample and generate signals based on real-world measurements, and others collect and process signal to do things like visualization, aberrant-behavior detection, and alerting and notification.
Below is an admittedly oversimplified diagram that describes how monitoring systems for things like human hearts and aircraft oil-pressure work (allowing, of course, for the omission of the more esoteric inner-workings of the human heart, which cannot be monitored). In it, we see sensors generating a signal that feeds the various components that provide operational feedback about the system to human operators.

All too often however, what we see in IT monitoring systems design looks like the figure below, where multiple sensors are employed to generate duplicate signals for each component that generates a different kind of feedback.
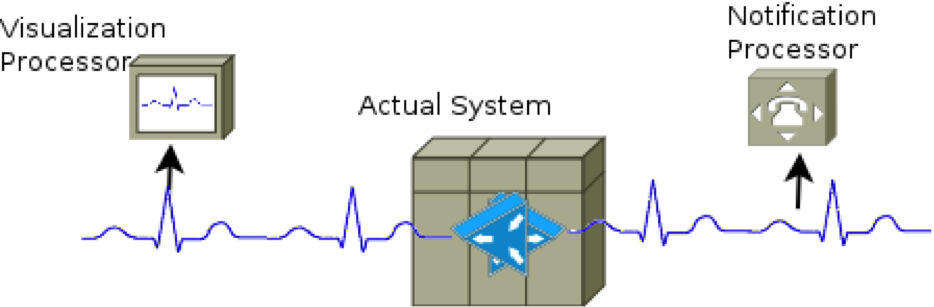
There are many reasons this anti-pattern can emerge, but most of these reduce to a cognitive dissonance between different IT groups, where each group believes they are monitoring for a different reason, and therefore require different analysis tools. The operations and development teams, for example might believe that monitoring OS metrics is fundamentally different from monitoring application metrics, and therefore each implements their own suite of monitoring tools to meet what they believe are exclusive requirements. For OS metrics, operations may think it requires minute-resolution state data on which they can alert, while development focuses on second-resolution performance metrics to visualize their application performance.
In reality, both teams share the same requirement: a telemetry signal that will provide closed-loop feedback from the systems they’re interested in, but because each implements a different toolchain to achieve this requirement, they wind up creating redundant signals, to feed different tools.
Disparate signals make for unpredictable results
When different data sources are used for alerting and graphing, one source or the other might generate false positives or negatives. Each might monitor subtly different metrics under the guise of the same name, or the same metric in subtly different ways. When an engineer is awakened in the middle of the night by an alert from such a system, and the visualization feedback doesn’t agree with the event-notification feedback, an already precarious, stressful and confusing situation is made worse, and precious time is wasted vetting one monitoring system or the other.
Ultimately, the truth of which source was correct is irrelevant. Even if someone successfully undertakes the substantial forensic effort necessary to puzzle it out, there’s unlikely to be a meaningful corrective action that can be taken to synchronize the behavior of the sources in the future. The inevitable result is that engineers will begin ignoring both monitoring systems because neither can be trusted.
Fixing false-positives caused by disparate data sources isn’t a question of improving an unreliable monitoring system, but rather one of making two unreliable monitoring systems agree with each other in every case. If we were using two different EKG’s on the same patient — one for visualization and another for notification — and the result was unreliable, we would most likely redesign the system to operate on a common signal, and focus on making that signal as accurate as possible. That is to say, the easiest way to solve this problem is to simply alert on what you see.
Synchronize your alerting and visualization on a common signal
Alerting on what you see doesn’t require that everyone in the organization use the same monitoring tool to collect the metric data that’s interesting to them, it only requires that the processing and notification systems use a common input signal.
The specific means by which you achieve a commonality of input signal depends on the tools currently in use at your organization. If you’re a Nagios/Ganglia shop for example, you could modify Nagios to alert on data collected by Ganglia, instead of collecting one stream of metrics data from Ganglia for visualization, and a different signal from Nagios for alerting.
Librato and PagerDuty are an excellent choice for centrally processing the telemetry signals from all of the data collectors currently in use at your organization. With turn-key integration into AWS and Heroku, and support for nearly 100 open-source monitoring tools, log sinks, instrumentation libraries, and daemons, it’s a cinch to configure your current tools to emit metrics to Librato.

By combining Librato and PagerDuty, all engineers from any team can easily process, visualize, and correlate events in your telemetry signals as well as send notifications and escalations that are guaranteed to reflect the data in those visualizations. Your engineers can use the tools they want, while ensuring that the signals emitted by those tools can be employed to provide effective, timely feedback to everyone in the organization. Sign up for a Librato free trial today and learn how to integrate PagerDuty with Librato .

