
Enabling Faster Incident Response and Mitigating Security Risks in Financial Services
by Joe Pusateri
July 14, 2021
| 9 min read
Software is eating the world. Digital Transformation is top of mind for companies looking to meet ever-growing consumer demands and digitize manual processes. This isn’t unique to the technology industry. Ecommerce, finance, healthcare, and other industries are all moving in this direction.
While customer expectations are increasing across industries, regulated industries, especially financial services, face heightened pressure to minimize downtime and security risks. We expect them to deliver services securely, and without interruption. No where does this ring more true than in the financial sector. Financial services impact millions of people and billions of dollars in revenue when they are down. In a competitive market filled with fintech startups looking to disrupt the industry, coupled with this higher standard of uptime and reliability, incidents can erode trust very quickly, sending customers looking for alternative solutions. Every second counts!
PagerDuty, partnered with AWS, can help teams uplevel their digital operations approach through better alerting, automated incident response, secure DevOps processes, and streamlined communication. Let’s take a look at how this works.
Get the Right Alerts with PagerDuty and DevOps Guru
Imagine that an online banking company is experiencing an incident where direct deposits are not showing up in application users’ account history. This is impacting a large group of customers and creating a lot of anxiety for them, and they want it fixed yesterday. This type of issue can quickly deteriorate trust and send customers packing. Not only does it need to be fixed right away, but ensuring this won’t happen again is critical for customer retention and trust. So let’s dig into what happens.
The incident response process kicks off when an anomalous delay is detected in Amazon’s DevOpsGuru and a new alert is sent to PagerDuty. This alert can be automatically correlated with any other similar open issues based on the configuration. This means that multiple alerts about the same problem (there could be lots of them) would all be grouped into the same incident, reducing the number of notifications that the on-call person has to acknowledge. There’s nothing more annoying than having your phone continually buzzing with a notification about a problem you’re already working on!
With its unique service-based architecture, PagerDuty automatically knows who is on-call for this service and type of issue. For critical, high-urgency issues, PagerDuty can call their phone, send them an SMS text, and send a push to their PagerDuty mobile app. This ensures that when the alarm goes off, the right person on the right team is quickly engaged to manage the incident response process. This is the first step in reducing the overall time it takes to fix issues: decrease the time it takes to start working on it.
But that’s just the beginning. It’s also important to leverage automation to ensure that the mitigation process proceeds as smoothly as possible.
Automate Incident Response with PagerDuty and EventBridge
But that’s just the beginning, imagine that the service delay is occurring on an AWS EC2 instance. During the response process, the person on call will typically begin investigating by running diagnostics to understand what’s going on. To do this, they will need to log in to the AWS Console (provided they have the credentials handy, are at the right authorization level, and hopefully haven’t expired). Leveraging PagerDuty’s Automation capabilities, the responder can easily trigger those diagnostics to run in AWS through PagerDuty’s Amazon EventBridge integration while the rest of the response team is notified in parallel.
One advantage of PagerDuty’s service-based architecture is that, while a team is interested primarily in alerts sent to its services from its own monitoring tools, PagerDuty provides responders with information about issues in other systems that are related to the one they are working on.
PagerDuty answers questions a responder would normally ask such as:
- What else is alerting now, and for how long?
- Has this issue occurred before? If so, when?
- What did we do about it before?
This historical information can be critical to deciding what steps to take, and giving the responders those answers faster saves time and money.
By the time the responder views the incident, it will be updated with the diagnostic results as well as this crucial historical information. This saves time and gives the responder the information they need to triage effectively and without needing direct access to the systems themselves. Where one might normally have to provision a login and give authorized access to many systems in order to run individual diagnostics, this saves configuration costs and allows for the safe delegation of tasks to responders via self-service.
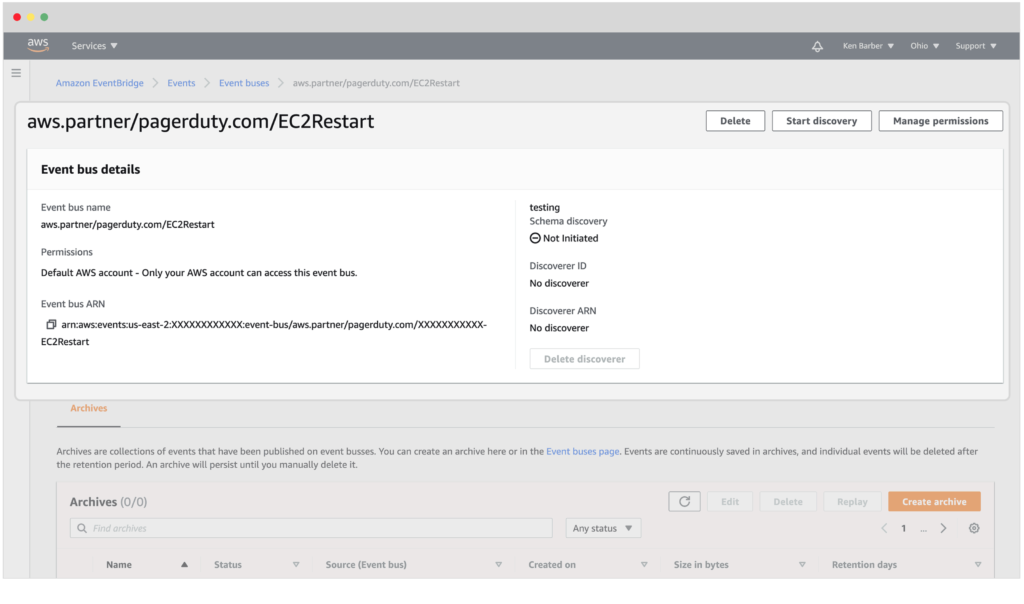
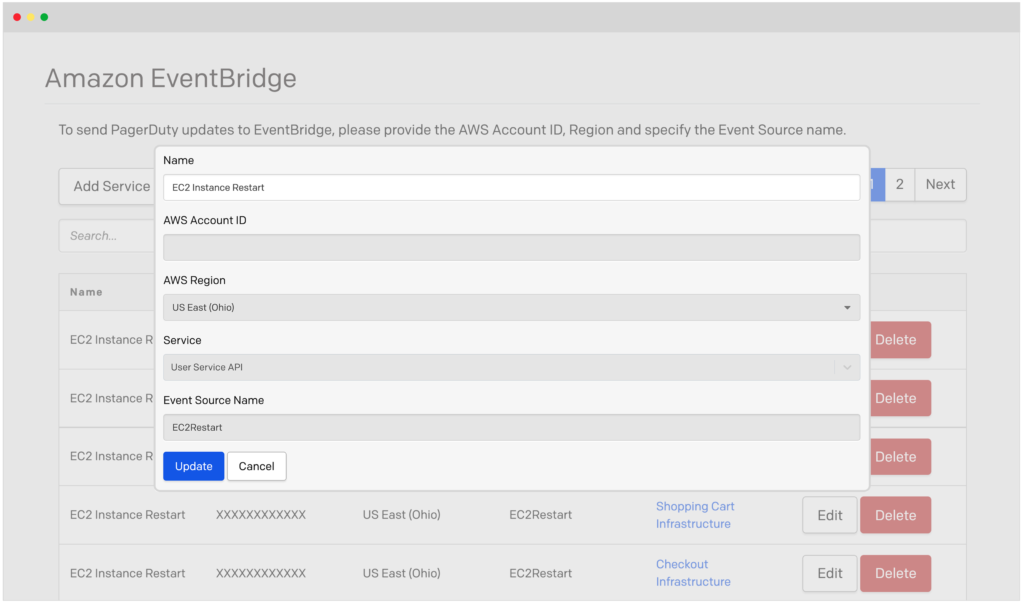
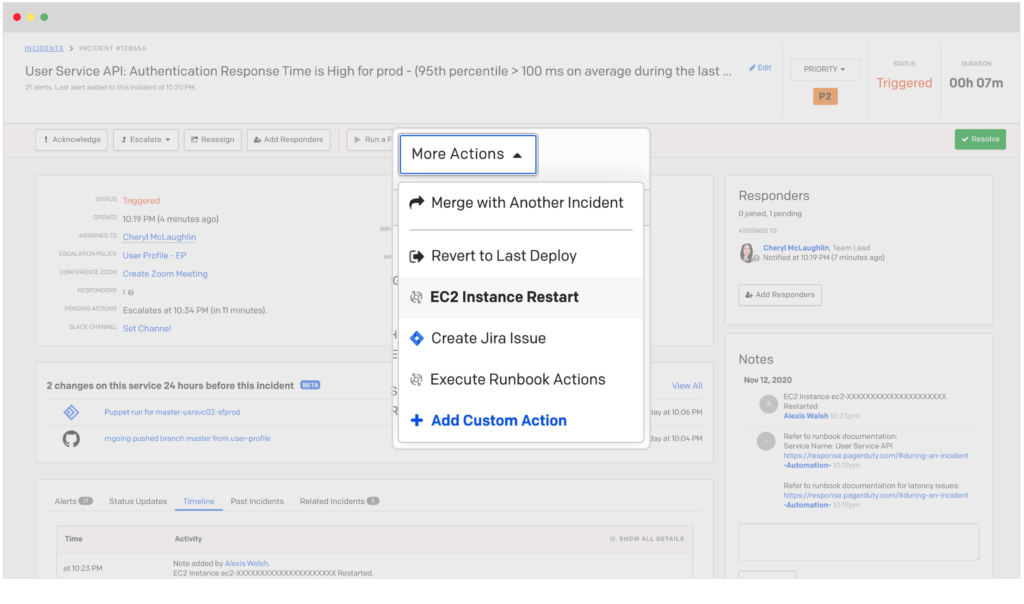
In this example, it turns out (based on the diagnostics) that the delay in processing is caused by an interaction with the database. The responder can’t fix it without calling in other experts. They are going to want to find the person on-call for that service. No need to look up who’s on which team or the latest vacation schedule, PagerDuty can call out to selected teams’ on-call responders at will. Just ask for the on-call person for the Database team to join the Incident and the responder and get back to troubleshooting the issue. When the additional responder or one of their backup members accepts the request, they can join a conference bridge or chat to coordinate with the rest of the responders.
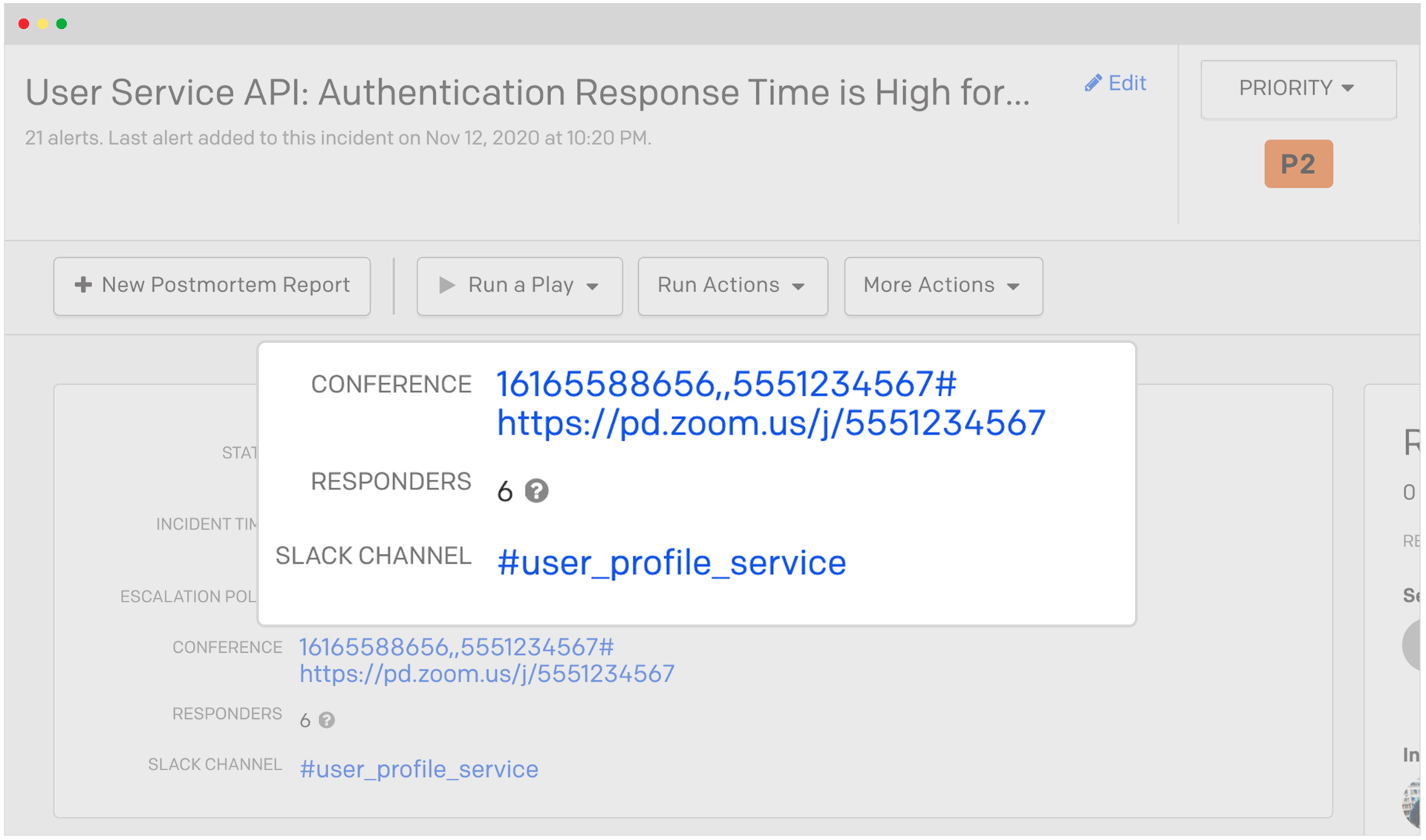
But, what happens in the event that the service was adversely impacted because of its dependence on another service, for example, an SQS queue? Applications and their underlying services are more complexly interrelated than ever. How can I know which other services my application relies on? PagerDuty is typically used by many different teams, each owning and managing their own monitoring tools and workflows. A service is PagerDuty’s way of distributing the management workload to each team, yet providing a unified view of the business impact overall.
In this example, the responders think the problem can be remediated by a quick service restart on the affected instance. PagerDuty can provide a menu item that the responder can select which will fire a script or command via EventBridge or PagerDuty’s RunDeck automation platform to complete this action. In fact, if this response is the default for repeat incidents, PagerDuty can run this script with no human intervention, while or even before any responders are notified! If we choose to wait before notifying anyone, it may be that the incident will auto-resolve without waking anyone up, which goes a long way to giving responders a better quality of life!
This example incident flow makes sense for an infrastructure or application error which can be triaged and remediated by a member of the DevOps team, but did you know that PagerDuty can also help for other use cases with AWS? Let’s look at a security breach for another example.
Stay Secure and Build Trust with PagerDuty and GuardDuty
The risk of a security breach is especially high for financial institutions. Setting up Amazon’s GuardDuty allows teams to intelligently monitor network activity, account access, and flows of data for anomalous or threatening behavior is a must.
Imagine in this new example that GuardDuty just detected a data pattern that points to unauthorized access on the network. Just as it did with the system degradation earlier, PagerDuty will find the right team and on-call person to notify urgently, because seconds count when a Security breach is underway.
In this case, we would set up Automation to perhaps reroute traffic, lock down the appropriate network segments, and isolate the affected components as soon as the alert is triggered and the Incident is created. In addition, the on-call Security Engineer will want to see a diagnostic snapshot. PagerDuty will initiate this and link the results to the Incident. By the time the Engineer views the Incident, all the relevant information is present and no time was lost in scrambling to prevent further damage.
An important part of this is that, no matter the engineer’s access level, the on-call person has access to needed diagnostic resources. Automation ensures that the least amount of privilege is given to the person and the underlying resources remain secure.
Keeping Stakeholders Informed and Incidents Blameless
Any time there is a high severity incident disrupting customer experience or possible security exposure, business service owners and other stakeholders will want to be informed. How long until we are back up? How many customers have been impacted? Has our data been exposed? These are all important questions, and those stakeholders need to be given attention. Unfortunately, gathering the relevant data, finding the right group of stakeholders, and crafting the right response slows down the responder from actually fixing the problem.
PagerDuty provides a channel to keep the relevant stakeholders up to date with messages just for them. Custom “response plays” can assign conference bridges and automate sending the relevant message to the right stakeholders, reducing the time responders spend managing the incident and allowing them to get back to focusing on fixing the problem.
Once the problem has been resolved, creating a blameless postmortem within the PagerDuty platform enriches the response process with learnings and generates best practices for that type of issue. Here, teams capture what they did right and what could have been better, providing an opportunity to continuously improve.
Empowering Financial Services Organizations to Shift Securely to the Cloud
Digital transformation can be especially challenging for financial organizations, but with the right ecosystem partners and digital operations management setup, they can navigate those additional compliance and security regulations while delivering high availability and seamless services to their customers. PagerDuty and AWS are enabling the financial sector to shift to the cloud safely and securely, while minimizing customer impact and downtime and speeding up innovation to keep up with customer demands.
Learn more about these PagerDuty and AWS integrations and many more at https://www.pagerduty.com/integrations/aws/.

