
Using Incident Management Data for Measuring Team Performance
by Patrick O Fallon
September 21, 2016
| 5 min read
When managing your ITOps team, it’s important to establish Key Performance Indicators (KPIs) based on real and actionable data. As the ITOps landscape evolves, your team’s responsibility and potential size will grow with it, paving the way for more resources and users to manage, and a greater variability across compute environments, configurations, and security. Now more than ever, you need to have a platform that provides a clear picture of your team’s performance and overall effectiveness.
What’s Hidden Inside the Analytics
Organizations adopt an incident management platform to move incident response from a reactive process to a proactive one. The solution can tell you what breaks and deliver the data to support a fast resolution. This value is obvious. But when I started working with PagerDuty, I found that there was a hidden gem that took the platform beyond just incident management. I was able to leverage the built-in analytics to measure my team’s performance and effectiveness with a new level of transparency.
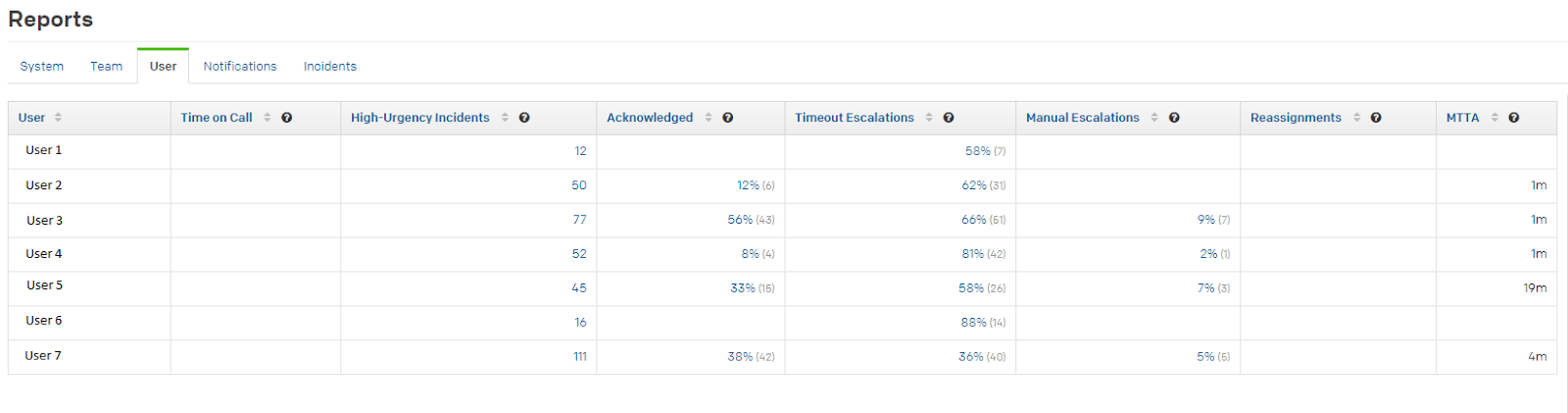 source: PagerDuty Analytics Dashboard
source: PagerDuty Analytics Dashboard
Spot top contributors
With the power of PagerDuty data, we were able to set up a system to reward those who responded to incidents.
From time to time, an on-call engineer ends up skipping calls or notoriously missing calls for high urgency incidents. This not only brings down the team’s effectiveness, but it also ends up forcing the accountable members of the team to shoulder more of the burden. By analyzing user-centric incident management analytics, we were able to quickly discover which team members not only acknowledge and respond to incidents but the percentage of team members that participated and executed their duties during a particular time period. Of course, the opposite is true as well, but we choose to lead by positive example.
If you open up the data to your team, it can be used for self-policing as well. For example, if a user is exhibiting high percentages of escalations based on no activity or “timeout escalations,” this visibility can help the team proactively take the right measures to tighten effectiveness before it causes an incident response problem that could affect SLA.
No incident response in a vacuum
Another problem we had was that incidents were acknowledged and resolved in a vacuum — the lack of analytics and reporting allowed for engineers to answer incidents without the rest of the team knowing they had, without any idea of what had happened. This creates a vicious cycle for ITOps teams, as the top performers can become beleaguered with no incentives to continue their excellent work, and in some cases, it can lead to engineer turnover. It also leads to critical, lost opportunities to learn from historical issues.
Metric-based rewards
Based on the analytics, we built an incentive program around who acknowledged and resolved the most incidents each month. This helped stimulate competition for engineers to be more productive.
Another example could be to reward your ITOps escalation team if they keep MTTA under one minute and the MTTR under one hour (or whatever metrics make sense for your team). Not only do these incentive programs stimulate your engineers and entire escalation team, they contribute to your effectiveness in maintaining your SLAs.
Below are some ideas on how to start incentivizing your incident response team:
- Incentivize the “Top Incident Responder” of the month.
- This could be the person who acknowledges the most incidents for the team.
- This could be the person who escalates the most unresolved incidents for the team.
- Incentivize the performance-based metrics for your team.
- This could be maintaining high urgency issues within a specific set of criteria.
- Reward the user with the most high urgency incidents assigned to them.
- Incentivize goal-oriented Time to Acknowledge and Time to Resolve.
- Incentivize metrics and responsiveness over time
- Reward your team for being ahead of where they were last month.
- Discipline metrics that end up below your SLA
- “Time On Call” is high, while “Number of Incidents Acknowledged” is low.
- High occurrence of “Timeout Escalations” from particular team members
- “Time to Acknowledge” and “Time to Resolve” higher than projected target
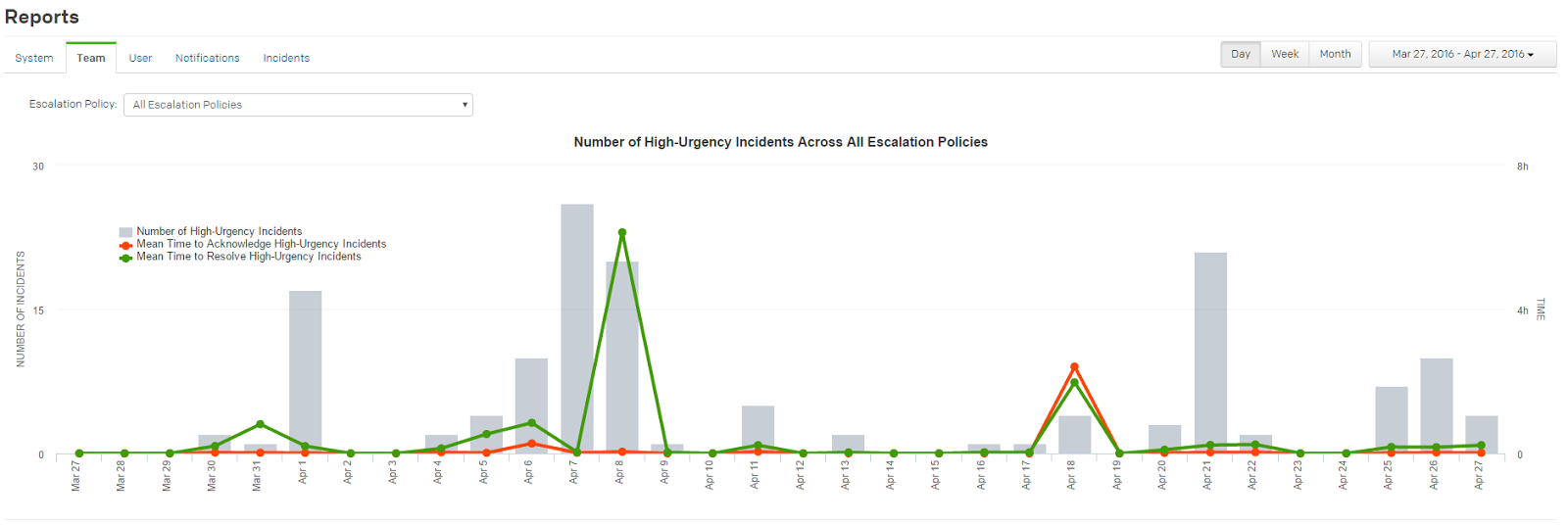 source: PagerDuty Analytics Dashboard
source: PagerDuty Analytics Dashboard
As the service level demands on ITOps continue to become more and more stringent, not only are operational challenges greater, management challenges are as well. If ITOps teams leverage existing tools to proactively learn, measure, and motivate their team, they benefit from both operational efficiency and team productivity. Incident management analytics in platforms like PagerDuty has become an invaluable resource to us, not only to confront these growing demands on IT but in streamlining the effectiveness and increasing the satisfaction of team members. It has given us more transparency, better learning, and a great way to measure and motivate every member of our team.
Ready to give PagerDuty a try? Sign up for a free trial.

