
- PagerDuty /
- Blog /
- Announcements /
- Announcing the Modern Incident Resolution Lifecycle
Blog
Announcing the Modern Incident Resolution Lifecycle
by Dave Cliffe
May 8, 2017
| 5 min read
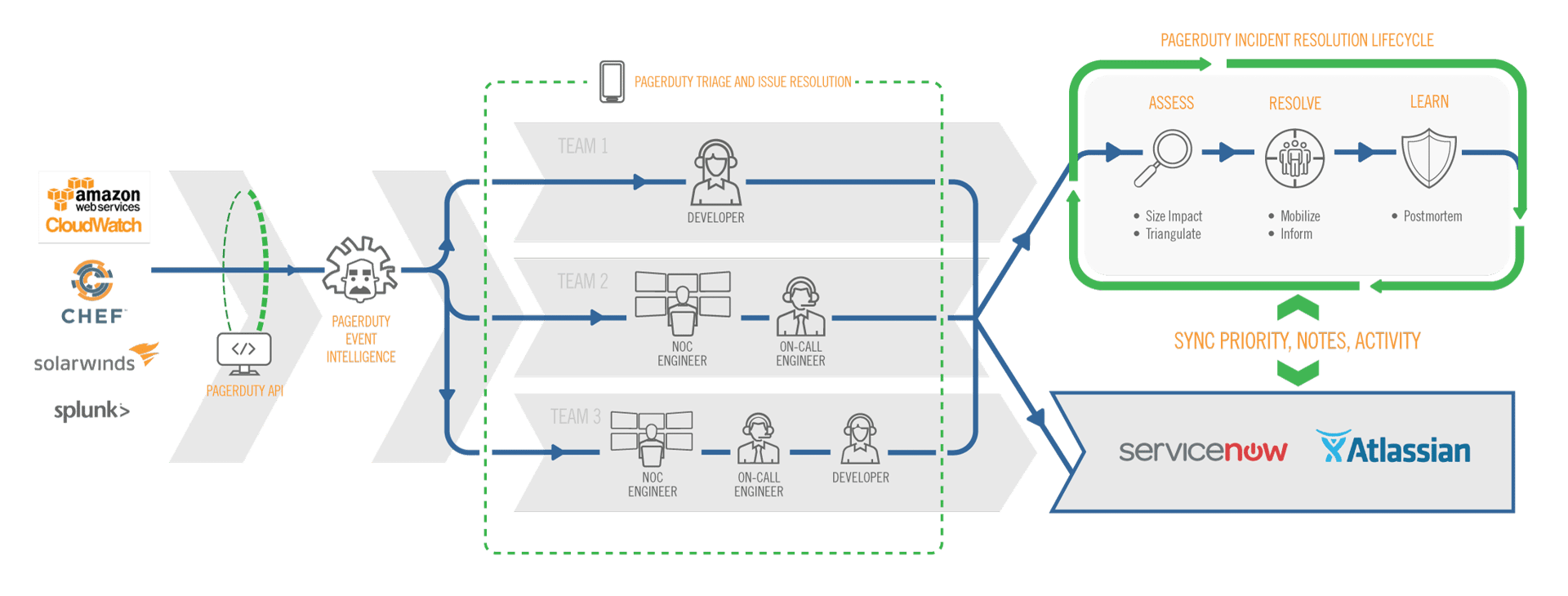
Today, we’re excited to announce a suite of new functionality to power even faster resolution and accelerate learning from major business-impacting incidents with the definitive Incident Resolution Lifecycle. With this release, we help you to differentiate major incidents from other day-to-day operational issues, and easily adopt best practices to streamline incident resolution and learning in your organization. These stages include:
- Assess — Enable responders to quickly diagnose local vs. global impact by using groupings of alerts and transparently communicating priority to others.
- Respond — Coordinate across teams, collaborate your way using tools of your choice, and engage stakeholders to orchestrate business-wide response and drive even faster resolution.
- Learn — Build postmortem timelines in minutes rather than hours and initiate the conversation on how to learn from past incidents and improve as an organization.
The Need for Better Incident Resolution
Complexity is on the rise. To meet the rising demands of customers, organizations are being forced to scale their operations in ways that introduce additional complexity and chaos. More people are involved in operations and in incident response, across an ever-increasing mix of systems, applications, tools, and layers of abstraction, resulting in more and more risk to the business.
As digital operations scale up within an organization — especially when developers are given operational responsibilities to own the services they build in production — one of the core challenges becomes ensuring the best possible customer experience during an outage. Organizations looking to improve their incident response must first establish consistent practices, roles, and terminology.
Own the Incident Response Process
Many organizations assign the role of establishing and refining the incident resolution process to one person or team. At PagerDuty, we benefit from working directly with our customers — some of the most mature digital operations teams in the world. Whether you choose to call it “insights engineering” or SRE (site reliability engineering), or simply, “major incident management,” the first crucial step is answering this question: what is an incident to your product or service?
1. What is an incident?
Distinguishing from day-to-day operational maintenance issues and customer-impacting incidents can be difficult, which is exactly why this assessment is best performed by the individual teams in their area of the product. Giving those teams a framework for triage decisions (P1 through P5, or Sev-1 through Sev-3, or whatever levels you decide to use) is fundamental to establishing common ground during a firefight. This new capability in PagerDuty now helps everyone distinguish major incidents from other minor operational or untriaged issues.
2. How do you respond to an incident?
The next step is establishing how your organization responds to incidents. If you can define clear roles for individuals involved in the response, this goes a long way in ensuring an effective process. Once again, PagerDuty’s open-sourced incident response best practices is a great resource for what we’ve seen commonly in operationally mature organizations and what we practice ourselves. We do actually practice the process in all circumstances, including during our Failure Fridays.
3. Own the Tools
The third and final step is also likely the biggest challenge: driving consistency of your process at scale. This is why we frequently see incident management process owners build or manage the tools they want the organization to use. In this area, PagerDuty aims to make organizational adoption of your process much easier in two ways: through automation and simplification.
Integrate Your Toolchain
If you are using an ITSM or ticketing solution such as ServiceNow or JIRA software (see all of our integrations), we are greatly expanding our integrations with both products to eliminate duplicate effort by responders or incident managers and ensuring the output of the assessment phase can feed seamlessly into your tool of choice. We are also introducing additional extensibility that allows you to create custom actions directly accessible via the incident in PagerDuty — simplifying troubleshooting by automating common tasks or remediations.
In order to streamline your process, we’re also introducing our new incident postmortem builder to help teams greatly simplify the act of reviewing and learning from a major incident. Post-mortems, also known as incident reports, post-incident reports, or root cause analysis, are critical for facilitating the right culture around continuous learning and improvement of both services and the incident response process. In addition, we’ve also expanded our permissions model to ensure that teams can manage their own artifacts while adhering to your top-level process.
As the leader in digital operations management, PagerDuty helps you scale both your on-call process and your incident resolution process, no matter where you are in your operational maturity. Do you own the incident resolution process or tools for your organization? Tell us what has worked for you and where we can continue to improve in order to better support you!
Check out all of our new capabilities by signing up for a free 14-day trial of PagerDuty.
Note: the Incident Priority functionality and our new JIRA Extension are both in limited availability for Standard & Enterprise customers at this time. Please reach out to support@pagerduty.com to enable it on your account.

