
- PagerDuty /
- Blog /
- Reliability /
- Lessons Learned from Creating a Reliable Mobile Build
Blog
Lessons Learned from Creating a Reliable Mobile Build
by Clay Smith
May 2, 2014
| 9 min read
PagerDuty engineers are obsessed with reliability. Letting down customers when they’ve been paged is the worst. With that in mind, we’re always designing and thinking of ways to maintain and build systems that maximize resiliency — including our mobile apps.
After the release of redesigned mobile applications last October, we’ve been shipping new features and updates that improve the reliability of those apps. From the perspective of a user, an app that consistently crashes or freezes is almost as bad as the services and APIs behind the app being completely unavailable.
After a total rewrite of the Javascript application embedded in our the mobile apps, the way we built and packaged our mobile applications was holding us back from quickly and safely releasing reliable mobile applications to our users. To move forward we had to rethink the way we created our Android and iOS apps.
Using software artifacts to simplify complicated builds
PagerDuty’s mobile apps are hybrid — most of the code that users interact with is a Javascript application inside of an embedded browser released on the app stores. This allowed us to simultaneously release a new version of the mobile application for multiple platforms with significant code reuse. We utilized the Apache Cordova project (you may have heard of it branded as PhoneGap) to provide us a consistent javascript-to-native interface that deals with strange issues and bugs with varying implementations of embedded web views. Cordova apps also can leverage a library of plugins that expose native functionality like accessing the address book.
Getting started with a Cordova app is straightforward to anyone who has written a web application. But the mechanics of packaging a pre-existing Javascript application inside of a PhoneGap project are considerably more complex. We tried several different approaches, but ultimately borrowing the idea of software artifacts from other programming languages (notably Java), we were able to create a less error-prone way to build our apps.
“Dependency Hell” is a Real Thing for Hybrid Applications
Cordova projects, by default, have developers put an html file in a “www” directory that’s the entry-point of the app. This code is shared between multiple platforms using various scripts bundled with a cordova project created from the command line. It’s an impressive effort of build engineering by the cordova team. When embedded a separate Javascript application that uses modern build tools like grunt or gulp and lives in a separate source control repository, though, things quickly get messy.
To get an idea of the complexity, here’s a diagram of PagerDuty’s mobile dependencies for 3rd-party code:
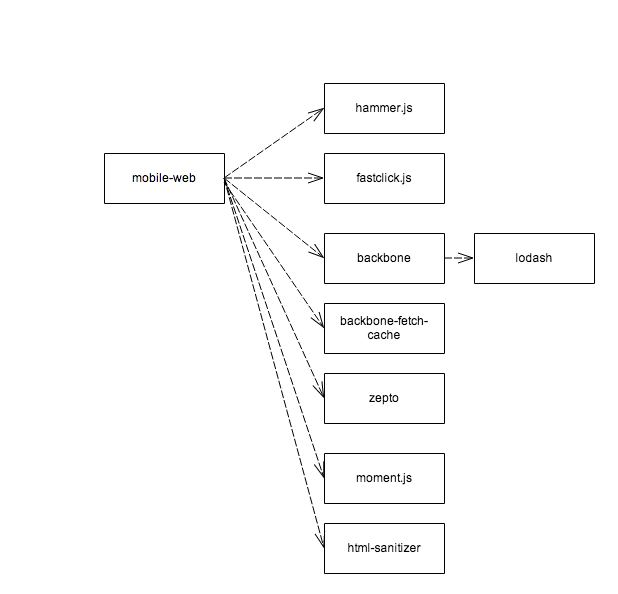
There’s also the complexity of the build tool itself. Here’s a diagram of the gulp.js packages that our default gulp task needs in order to build a PagerDuty’s app. The build process (among other things) compiles from coffeescript, concatenates files and creates front-end templates:
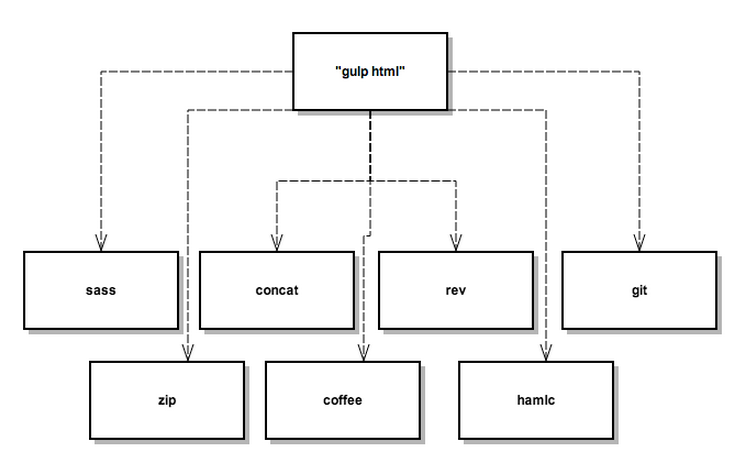
This complexity in the build is driven by a need for the best performance. To build a decent cross-platform mobile app in Javascript, it’s all-but-required that specialized libraries are needed to handle extreme device fragmentation and various platform quirks. The Javascript code itself needs to be transformed to run optimally in browsers as well.
Ultimately, though, all we care about is a standalone index.html file that loads css, javascript, images and web fonts. It works on any static web server or locally on a filesystem. That’s what we want to package and send to different platforms:
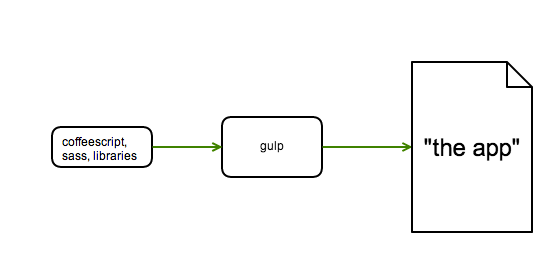
Building a Javascript application this way gives us the most flexibility, but we also had to answer all these questions:
-
Which libraries should I use? (jQuery vs Zepto, Hammer.js, Backbone vs Ember vs Angular vs React)
-
What templating language should I use? (handlebars vs underscore templates vs mustache)
-
Should I use a library dependency manager like bower.js or component.js (or just npm)?
-
Which build tool? (gulp vs grunt vs rake vs ant vs browserify)
-
What testing framework? (qunit vs jasmine vs tap)
-
Do I bother writing in Javascript (coffeescript, dart, typescript, clojurescript)?
-
How are you going to use NPM?
It’s an insane amount of choice and it reflects the anarchy of building front-end Javascript apps “the modern way”. We learned a few things along the way when we tried and inject an app built this way into native mobile applications.
Lesson 1: Please don’t check in transformed Javascript source to VCS
We’ve known for a very long time it’s not ideal to check binaries into source control. Source control works best for plain-text files that change in predictable ways and bad things happen when git tries to resolve a merge conflict with two concatenated and minified javascript files. Constant merge conflicts are very disruptive to developer workflow (particularly for larger teams). Disk space is cheap, but for long-lived repositories with large amounts of Javascript code
It’s easy to ignore this advice, though. Check any popular javascript library on github and there’s likely some sort of “dist/” folder sitting there. It’s a fast way to iterate, but the intricacies of developing an application on a team using git with a complicated build process become a burden. We thought there had to be a better way.
Lesson 2: Leverage tools you understand and know how to use, but understand their limits
We realized, of course, that checking in our heavily transformed code into git wasn’t working. But there’s no real build artifact repository manager that front-end developers commonly use. Ivy, Maven and Archiva are very familiar with this problem but they aren’t well suited or particularly familiar to someone writing Javascript.
There was a tantalizing alternative, though. What about npm? It has lots of great things going for it, we understood how it worked. If we put a package.json file inside of our native application repositories, it’d only take a quick “npm install” to fetch our mobile application repository (which was a CommonJS repository) and all of the dozens of dependencies it needed to build itself. Our package.json looked just like this:

Instead of fetching a published package, NPM fetched our project from private github repository at a particular commit, allowing us to arbitrarily point to different revisions. We then had another script that ran gulp.js and built the app after it had been fetched. Magically, we eliminated all of the checked-in compiled and transformed code into github. We just needed to generate the app before bundling it inside of native applications.
Locally, it was easy enough to have a build step in XCode or Gradle that ran “npm install” and ran a few tasks in our Javascript build tool. It became a problem as our native applications started running in different environments, though. We were injecting all of the complexity and intricacies of a complex Javascript application into environments that only needed a couple static files. XCode, for instance, suddenly needed to know (via some shell script) how to compile coffeescript. In order get a continuous integration working with TravisCI, we would also have to install node, npm, and all of the other build dependencies on their Mac OS X images.
NPM came so close, and perhaps with a privately-hosted npm repository we could have made it work. Using github as the source for our app package, though, the only way we could have reduced complexity in our native builds would have been to check the transformed source code. We needed to use something that had a concrete idea of build artifacts.
Lesson 3: Ask, “Do we already know the best practice?” or “Have we already learned this somewhere else?”
In September 2013, github released their Release API. It allows developers to create a release object with a tag in git repository. More critically, it also has the concept or an arbitrary number of artifacts associated with each release. In other words, we had a pseduo-artifact repository built on top of our revision control system that was already part of our daily workflow.
Using a couple of simple ruby and shell scripts (or the Github UI directly), we could create a tag that pointed to a particular commit, create a new release from that tag, and then upload a zip archive of all of the html, Javascript and CSS that powered our webfonts.
Any build or platform that consumed our app would only need to know how to fetch things over HTTPS and be capable of running a Javascript application.
While we could have used a more professional artifact manager like Ivy or Nexus (or even stored artifacts in some sort of cloud storage like Box or S3), the github integration made it particularly easy.
Embracing the anarchy of Javascript apps
While NPM has largely solved this problem for server-side Javascript, it’s 2014 and we still don’t have a widely accepted and supported method to package front-end Javascript applications that target multiple platforms. There’s no real equivalent of something like a Java JAR archive. However, I don’t think that’s a problem or even desirable. Javascript libraries and tools are thriving in the current system and it would be incredibly difficult (if not impossible) to get the current community or standards bodies to coalesce around some sort of single, packaged “app-standard” that runs in Android, iOS, Firefox OS, Chrome OS, or other platforms.
The idea of a single HTML page that loads Javascript, CSS, web fonts, and images is fundamentally portable. Any browser load an index.html file. When it’s packaged inside of a ZIP archive and stored in some sort of repository (ideally one that’s designed to handle build artifacts), we can create a simpler, more reliable build that lets us release faster with more predictability.

