
- PagerDuty /
- Blog /
- Operations Performance /
- Increasing Quality and Reliability with Continuous Integration
Blog
Increasing Quality and Reliability with Continuous Integration
by Ranjib Dey
April 14, 2014
| 8 min read
Continuous integration (CI) is a software development practice where members frequently merge their work to decrease problems and conflicts. Each push is supported by an automated build (and test) to detect errors. By checking in with one another frequently, teams can develop software more quickly and reliably. In essence, CI its about verifying the quality of code to ensure no bugs are introduced into the production environment. If there are bugs found in testing, the source is easily discovered and fixed. By testing the code frequently after every commit you can shrink the investigation around the source of the bug to the shorter time period. But manually testing the code is a pain and redundant. Many tests can be reused so we have created multiple automated tests to make it easier to test frequently. Additionally since these tests are iterative, once a bug is found we’ll create a test that looks for it in future code reviews so old bugs are never introduced again.
Before an Automated Build
 At PagerDuty after we decide on what we need to build a JIRA ticket is created to easily collaborate and to keep members updated on the status. Inside the ticket we include information around what this feature or fix will do and what the known impacts are. Then we create local branches from our Git Repo for the feature we want to develop or issue/bug we want to fix and give it the same name as the JIRA ticket. Git is a Distributed Version Control System (DVCS) so there is no a single source repository where we take the code from but there are multiple working copies. This prevents having a single point of failure in traditional single source repositories which relies one physical machine. We’re all about redundancy here at PagerDuty (multiple databases, multiple hosting providers, multiple contact providers for multiple contact methods, etc.) so having a DVCS makes it easier for us to develop locally even when there are issues. Bazaar and Mercury are few other DVCS you may want to check out.
At PagerDuty after we decide on what we need to build a JIRA ticket is created to easily collaborate and to keep members updated on the status. Inside the ticket we include information around what this feature or fix will do and what the known impacts are. Then we create local branches from our Git Repo for the feature we want to develop or issue/bug we want to fix and give it the same name as the JIRA ticket. Git is a Distributed Version Control System (DVCS) so there is no a single source repository where we take the code from but there are multiple working copies. This prevents having a single point of failure in traditional single source repositories which relies one physical machine. We’re all about redundancy here at PagerDuty (multiple databases, multiple hosting providers, multiple contact providers for multiple contact methods, etc.) so having a DVCS makes it easier for us to develop locally even when there are issues. Bazaar and Mercury are few other DVCS you may want to check out.
Write Tests First
Although it would be nice to have automated tests for everything we build, it takes time to build them. Our tests are created before the code is written so we can use them to govern our designs and to avoid writing code that are hard to test. This test-driven development (TDD) improves software design and helps us maintain the code more easily. We prioritize test criteria in the order below since they have the greatest impact on reliability and resources.
1. Security – Critical bugs that block our workflows fall in this category. If the fix mutates any business critical code path we want to make sure we have everything tested.
2. Strategic – Large scale code rearrangement, adding new features. These tests tend to add corresponding specifications in our test suite. This addresses both happy path scenarios as well as any known regressions. For example, adding different types of services/micro services (a new persistent store) or a new tool (that automates a repetitive long running manual work).
3. Consistency – As a growing team, we need to make sure that the code built is easy for someone new to understand to build on top of. This exercise is an established best practice for code quality, error handling and identifying performance issues. Anyone who knows chef should be able to understand our code base. For example, isolation of our customizations and capturing them as separate patches/libraries then sending those patches to upstream projects. In these scenarios we write specs for the integration layer (i.e the glue part that ties out extensions with external libraries, like community cookbooks, gems, tools etc).
4. Shared Knowledge – Every functionality has a valid or certain domain assumptions. We use tests to establish what those domains are to know the boundaries of a feature. These are very specific to our own infrastructure, its dependencies and overall topology. An example is how we generate search driven dynamic configuration files for different service (like we always sort search results before before consuming it). We write tests to validate and enforce these assumptions, which is also exploited by downstream tool chains (like naming conventions across servers, environments etc.).
Our Testing Suite
The tests we write fall into 5 categories. All code built must pass tests in the order below, except for load tests, before it is deployed to maintain quality and reliability.
Semantic tests: We use Lint checks for overall semantics of the code and common best practices and Rubocop for ruby linting and Foodcritic for chef specific linting. These are code aware tools so depending on the language you write in these tools may or may not work for you. Lint tools are applied globally after every commit and we don’t have to write any additional codes for this.
There are several occasions when lint tests caught actual bugs apart from pointing at styling errors. For example foodcritic can detect chef resources that does not send notification when updated.
Unit tests: We write unit tests for almost every bit of code, if we are developing chef recipes, chefspec tests are written first. If we are writing raw ruby libraries, rspec tests are written first. Lint and unit tests don’t look for functionality. They are testing if the code has good or bad design.
Good design makes it easy for other members to pick up the code and understand it quickly. Additionally these tests show how easy it is to decouple the code. Technology is ever changing and the code has to be flexible. If ubuntu or nginx releases a patch for security reasons, how easy is it to accept that change
Functional tests: These test are intended to verify the feature of functionality as a whole, without any implementation knowledge, without mocking or stubbing any sub component. Also we strive to make the functional specs as human readable as possible, in simple english, without any programming language specific constructs.
These tests help out with:
new server provisioning
existing server teardown
an entire cluster provisioning
whether a sequence of operation works or not
We use Cucumber and aruba to write functional tests. These tests are not concerned about how the code is written but only if works. Cucumber is a BDD tools that allows specifications to be written in a readable fashion (using gherkin), while aruba is a cucumber extension that allows testing command line applications. Since a vast majority of our tools provide a command line interface (CLI) we find these testing tools very handy and easy to use.
Integration tests: These tests make sure everything is working when combined with all other services within a production like topology against a production like traffic pattern. This also helps us answer whether our system automation suite will work perfectly alongside different services, and against every changes made in them or other third party services that we consume.
Load tests: This will help us determine at what traffic scale we can handle. And quickly identify the main performance bottlenecks. We do a series of setup tasks to ensure we have production like data volume. Generally these tests are time consuming and resource intensive, hence they are performed periodically against a set of code changes (batching). Code changes where we feel performance is not a concern (config changes, UI tweaks), at times by pass these tests.
Automating Deploy & Sanity Checking
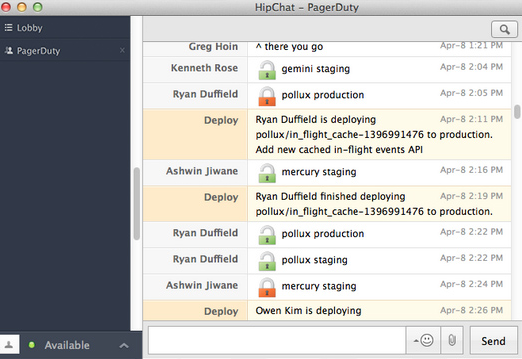 After the code passes all the tests we hand the code off to another team member to do a sanity check before releasing it. We do manual code overview to get a 2nd opinion to ensure that bugs aren’t introduced into production. The peer code review helps to ensure that no requirements were missed and that the code meets design standards.
After the code passes all the tests we hand the code off to another team member to do a sanity check before releasing it. We do manual code overview to get a 2nd opinion to ensure that bugs aren’t introduced into production. The peer code review helps to ensure that no requirements were missed and that the code meets design standards.
We follow a semi-automatic deployment, where CI assist in testing and project specific tools (like capistrano and chef) and assist in deployment, but the actual deployment process is triggered manually. The deployment tool itself will send a message in the PagerDuty HipChat room to let everyone know when something is being deployed. Then it sends both pre-deployment and post deployment notifications (as lock and unlock service messages). This helps us understand what is being deployed and also to avoid concurrent deployments.
With Continuous Integration we create a baseline quality of software that must be met and maintained which lowers the risk around our releases.

