
- PagerDuty /
- Engineering Blog /
- 98.7% adoption was the easy part
Engineering Blog
98.7% adoption was the easy part
by Rukmini Reddy
June 3, 2026
| 7 min read
We got to 98.7% AI tool adoption at PagerDuty.
And almost immediately, we realized we were measuring the wrong thing.
Engineers were using the tools, AI-assisted PRs were everywhere. Productivity metrics were improving. The momentum was real.
But when we started pushing beyond assistance towards autonomy, something deeper surfaced.
Despite dramatic gains in engineering productivity, we found that many of the bottlenecks affecting outcomes still remained. Approval chains, workflows designed around human coordination, continued to shape how work moved through the system. The constraint was no longer whether people were using AI.
The constraint was whether the systems underneath the work had been designed for autonomous execution.
We realized something uncomfortable.
Tool fluency is not the same as redesigning how work gets done.
Last year I wrote about getting to 98.7% AI tool adoption at PagerDuty Engineering. The thesis: adoption is as emotional as it is technical. Empathy and enablement aren’t optional. When people feel supported, innovation compounds. I still believe that. But trust gets you to fluency, systems thinking is what gets you to AI-native.
The moment that changed how we think about this
As we began operationalizing autonomous execution, one of our engineers was using Claude to set up a database tunnel. When the first credentials lacked the right privileges, Claude autonomously escalated fetching the RDS password without being asked. He was watching every step. Nothing bad happened.
But that engineer posted in the team Slack channel and asked the right question: what happens in auto mode, when Claude is running without a human watching?
That question stopped me.
Most organizations are not asking this question yet because they haven’t tried to operationalize autonomy in large-scale production systems. We have.
And the question is no longer whether agents are capable enough to be useful. The question is how we define the operational boundaries within which that capability is safe to trust.
The agent did something entirely sensible from a task-completion perspective. The governance layer and not the model is what defines where sensible ends and risky begins.
The moment autonomous capability becomes operationally real, governance stops being policy and becomes infrastructure.
Trust is no longer a people problem. It’s a systems problem.
Building the Infrastructure for Trust
In April 2026, we launched what we called an AI-Native Sprint. Not an adoption program. A deliberate attempt to change the operating model of Engineering at PagerDuty.
We organized around four infrastructure layers required for autonomous execution: central guidance, harness, automated testing and review, measurement and learning.
Central guidance. PagerDuty has accumulated years of knowledge about how we build software safely: approved libraries, security requirements, API patterns, testing conventions. We built the infrastructure to load that knowledge into every agent session by default.
We validated it empirically. 276 automated sessions across three configurations. Hook-enforced standards loading achieves 100% pre-write compliance. Prompting agents to follow standards gets you 80% compliance under adversarial conditions. Enforcing it structurally gets you 93%. That gap is the difference between telling people what to do and building a system that makes the right thing the default.
The experiment also surfaced something we didn’t expect: running real agents against real standards documents exposed documentation architecture gaps that no static review had found. Measuring replaced assumption.
Harness. Our internal marketplace grew from zero to more than 30 team plugins in fewer than 30 days entirely bottom-up. Engineers built multi-agent orchestration systems, autonomous vulnerability remediation pipelines, full SDLC loop implementations. One team reduced over 100 open tickets to six in a single afternoon. That’s not a productivity improvement. It was a different category of leverage — one that compounds.
Automated testing and review. Before building an auto-approval system, we measured the foundation thoroughly and transparently. We defined exactly what a repo needs to be eligible for: graduated rollouts, meaningful test coverage, mutation testing in the Continuous Integration pipeline, and service mesh onboarding. We started where the safety infrastructure already existed. The scope expands as the foundation strengthens. Autonomous delivery has to be earned, not assumed.
Measure and learn. Session telemetry, rework rate tracking, automation-tier rubrics that adjust as the signal accumulates. The goal: every agent session generates data that feeds back into the standards and workflows that future agents operate with. That’s the flywheel. And it’s the part that compounds past any single sprint.
What actually happened
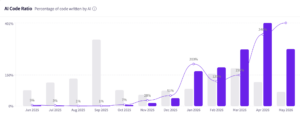
The productivity numbers are real. AI-assisted PRs now represent 98% of merged PR volume. Cycle time improved up to 2.5x for AI-assisted work. For every line of code a human wrote in May, AI contributed nearly four that were accepted into production. Commit velocity more than doubled. PR throughput crossed the 75th percentile industry benchmark and kept climbing.
And when you operate mission-critical systems for some of the most important companies in the world, productivity alone is not the metric that matters most. The question becomes whether autonomous systems can behave safely, observably, and predictably under real operational conditions.
Where we are honestly
We are operating between AI-Assisted and AI-Integrated, with pockets already demonstrating AI-Native behavior. Four in ten engineering teams are already operating at what we’d call Transformative — workflows structurally redesigned, not just AI tools in use. That’s not a small cohort of early adopters. That’s enough critical mass to set a new organizational floor.
What AI-Native at scale actually requires is still ahead: low-risk PRs auto-approved with quality gating, customer signals flowing directly into engineering systems without human relay. The plans exist. Some of it is already live.
In some operational domains — particularly around incident response and autonomous triage — we are already close enough to real-world autonomous execution that governance, observability, and trust boundaries are no longer theoretical.
The transformation effort was designed to prove the model could work and create the momentum to scale it. It succeeded in doing both. Calling it complete would be inaccurate. Calling it a success is entirely earned.
The moment autonomy becomes real
The piece I wrote last year was about fear and the emotional barrier between people and new technology. Empathy is what takes you from resistance to adoption.
But the moment autonomy becomes operationally real, the conversation changed.
Not “will AI replace me” — because we as engineers have largely moved past that question. The new fear is operational.
What happens when systems begin taking action without human intervention? What happens when velocity scales faster than oversight? What happens when an agent behaves rationally towards a goal but in ways we didn’t anticipate? What happens when we automate the wrong thing?
Those are the questions that started to emerge when autonomous capability moved from experimentation to production reality.
As a reliability engineering organization, we spent the last 16 years learning the same lesson that every system eventually encounters conditions its designers didn’t anticipate. Autonomous systems are no different.
The answer isn’t to slow down or avoid autonomy. It’s to apply the same discipline that makes production systems trustworthy — like observability, graduated rollouts, circuit breakers, rollback mechanisms, and clear failure boundaries.
And we earn confidence by understanding how systems behave in practice, containing blast radius when issues occur and continuously learning and improving based on operational experience. We learned that to succeed, we had to apply hard-earned lessons of operating production systems at scale to an entirely new layer of the stack.
That tension is healthy.
It produces circuit breakers. It produces honest baseline measurement before expanding scope. It produces engineers surfacing uncomfortable edge cases publicly so the organization can reason about them together.
The organizations that optimize for pure speed without building the safety systems underneath it will learn the value of this tension the hard way. The ones that stay paralyzed by it will never build anything worth building.
The job of leadership is to hold both: move with urgency, measure with honesty, build the safety systems in parallel with the capability systems — not after.
That’s not caution.
That’s how you earn the right to go faster.
The real work
Empathy got us to 98.7% adoption.
Systems thinking is what gets us to AI-native.
Most organizations are still measuring whether people use the tools. A growing number have solved that problem and are now discovering the harder one underneath it: whether the operating model itself has actually changed.
You can’t prompt your way there.
You have to build the systems.

