- PagerDuty /
- Blog /
- Best Practices & Insights /
- How to Avoid the Executive ‘Swoop and Poop’ and Other Best Practices for Operational Maturity
Blog
How to Avoid the Executive ‘Swoop and Poop’ and Other Best Practices for Operational Maturity
by Hannah Culver
August 11, 2021
| 7 min read
We’re eating at restaurants again. We’re seeing family after too long apart. Some of us may even be returning to the office. But, that doesn’t mean that the pressure is off for digital services, and growing in operational maturity still remains top of mind.
While the digital transformations have been taking place for the last two decades, COVID-19 added pressure to speed initiatives. Teams experienced more incidents during this time, and, as the lines between work and home blurred, many people began working extended hours to firefight.
In fact, in a survey of over 700 developers and IT operations professionals, 58% of respondents say that in a 3 to 6 month timespan, incidents have grown by more than 40%— with an average increase of 47%— placing significant pressure on their teams.
In talking with customers about how they’ve adapted in this environment, there is a clear distinction between cohorts of organizations and teams in their operational maturity. In short, the more mature an organization was, the easier they adapted to the changing pace and increased demands. But before we get into that, let’s take a step back. What exactly is operational maturity?
Operational maturity is a measure of the overall consistency, reliability, and resilience of IT infrastructure, including how it is managed and maintained. This encompasses how teams deal with incidents. Operational maturity affects the health and happiness of the teams supporting this infrastructure, as well as the end user, making it an increasingly key investment.
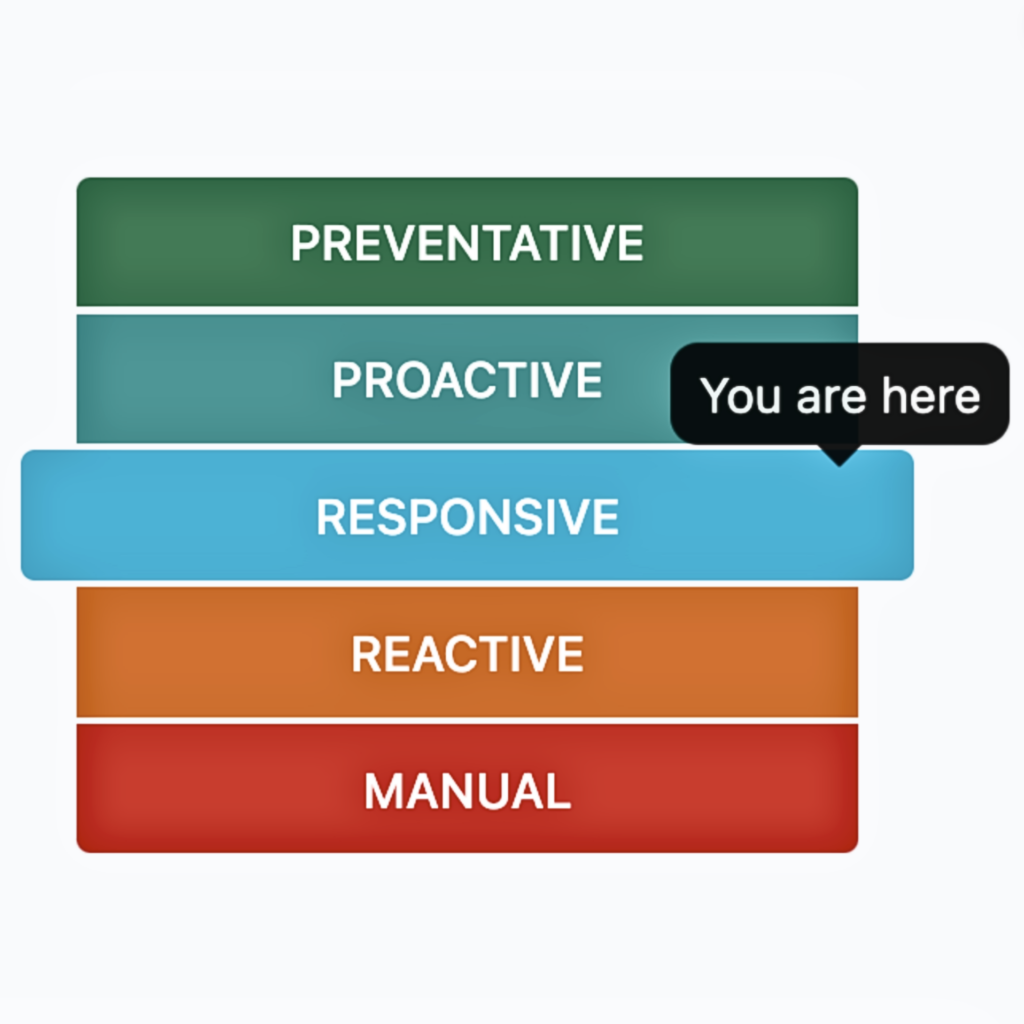
We’ve determined that nearly all organizations fall within 5 categories of operational maturity: manual, reactive, responsive, proactive, and preventative. Reaching the next level of operational maturity requires process, tooling, and cultural changes. We’ve created a webinar to help teams understand where they’re at now, and how to improve.
To give you a taste of what will be covered, here are three best practices that you’ll learn from our speakers:
Make Incident Response a Business Response
Think about a crew of firefighters. When responding to a major fire, they have a chief to delegate the process (who doesn’t actually do any of the firefighting themself), a navigator and communicator, as well as several firefighters who are actively putting out the fire. Incident response works in a similar way. Operationally mature teams will have designated roles for major incidents. They’ll have a commander who organizes the efforts, a communications lead who shares new developments, as well as several subject matter experts (SMEs) who are resolving the incident.
But business incident response goes beyond just involving the service owners and direct responders. The most mature teams also make sure that other business stakeholders are kept in the loop throughout the process. This is a task often handled by the communications lead.
In major incidents, more than a single team will need to be aware of the issue. For example, customer support needs to know they should expect a higher volume of calls and tickets. Sales might need to postpone demos or calls. Marketing might need to know to hold back on a particular social post, or anticipate higher-than-average media attention. Executives will want to know the overall business impact of not just the technical team involved, but the impact of all these teams jointly.
By communicating with stakeholders, updating them on new developments, and working together sans siloes, incidents are resolved faster and have a smaller customer and brand impact. Additionally, this helps avoid the “swoop and poop,” a term for when other line of business stakeholders interrupt incident response efforts to try to understand how this will affect their teams. Proactively addressing their concerns before they ask can save time and energy for the responders.
Learn from Mistakes and Make Changes
Incidents happen. You can’t avoid them. But, you can learn from them, and, in some cases, even prevent the same class or type of incident from happening again. This depends on how well your team learns from failure, and is another hallmark of operational maturity.
Postmortems are an important way to learn from system failures. After an incident is resolved, operationally mature teams go to work to determine both why this happened, and how to prevent it from happening again. This process usually involves creating thorough documentation on the incident, including timelines, scripts or runbooks used in the resolution process, and relevant telemetry data.
After the documentation is finished, the response team will assemble (virtually or in person) and discuss the events, potential root causes, how the process worked, and what can be done to make the system more resilient to this type of failure. It’s important in this process to approach failure blamelessly to preserve psychological safety and reap the most benefits from this process.
After the postmortem is complete, teams are often left with a list of action items that could protect the system against a similar failure. It’s not enough to create these action items and leave them unassigned in a queue. Part of operational maturity is also taking action to make positive changes.
Not all action items are created equal. Some are of higher value than others. When considering which action items to prioritize, examine them through the lens of impact to the overall business. If two action items are scoped to take the same amount of time, yet one will benefit only the service owners and one will benefit a larger portion of the business, prioritize the one that will help more people.
Measure Burnout Both Qualitatively and Quantitatively
Incidents are unpredictable. That’s why they’re deemed unplanned work. If we could all plan our schedules around foreseen outages, life would be much easier. However, it doesn’t work like that and interruptions are inevitable. If these interruptions are very frequent, or happen during non-working hours such as nights, weekends, and holidays, on-call team members might begin to feel burnt out.
A recent report by PagerDuty showed that through 2020, the average PagerDuty user worked 2 hours more per day than they did in 2019. That equates to 12 extra weeks of work annually. Additionally, the report found that users who experienced more off-hour interruptions were those who most commonly deleted their PagerDuty accounts (our proxy for attrition). Companies need to catch burnout early before it results in lower team morale and attrition.
How can organizations do this? Quantitatively, managers should be looking at time spent on call, average number and duration of incidents per on-call period, and how often their teams are pulled away from their lives during non-working hours to respond.
But the tale of burnout isn’t solely told in numbers. Getting a qualitative feel for how teams are faring is just important. For instance, managers should listen for chatter about late nights, or team members feeling overworked. They should also be cognizant of any decreases in work quality, or missed deadlines which can be indicators of burnout. Last but not least, managers need to keep a pulse on team morale and ensure that, though many of us are still remote, there’s an open-door policy for any concerns.
If teams can focus on preventing burnout, resolving incidents as a business rather than just a team, and learning from mistakes, they’ll be well on their way to operational maturity. But that’s not all that this transformation requires.
Our webinar, “Deep Dive on Operational Health,” covers how you can plan to mature your organization. Join PagerDuty’s Mandi Walls, DevOps Advocate, and Logan Life, Senior Principal Customer Success Manager as they walk through tactics for how to grow in operational maturity and tackle DevOps best practices such as full-service ownership and cultivating a blameless culture.
Register to watch the on-demand webinar.