
- PagerDuty /
- Blog /
- Partnerships /
- Using AI / ML to Supercharge Continuous Delivery With Harness and PagerDuty
Blog
Using AI / ML to Supercharge Continuous Delivery With Harness and PagerDuty
by Steve Burton
September 7, 2018
| 4 min read
At first glance, applying machine learning to Continuous Delivery might sound a bit like cracking a peanut with a sledgehammer. I mean, how hard can deployment automation actually be?
As it turns out, it’s way more complex than we think.
Pushing a new deployment into production typically has two outcomes:
- The service stays up and we think everything is OK.
- The service doesn’t stay up and all hell breaks loose.
The reality is, these two points above represent how 95 percent of organizations measure deployment success (up=good, down=bad). Those of you who are happy PagerDuty customers will be most familiar with outcome No. 2 (from the storm of alerts/incidents that hit your cell phone). However, Scenario No. 1 is also misleading because a Service staying up doesn’t automatically imply health, performance, or quality.
Disadvantages of Manual Deployment Health Checks
One thing we learned from our first 25 customers at Harness is that most organizations typically have 3-5 engineers who each spends at least an hour to manually verify production deployments For example, one of our customers, Build.com, used to have 5-6 team leads spending an hour each manually analyzing data from New Relic and Sumo Logic—which usually means having multiple console/browser windows open and context toggling between bash scripts, application performance monitoring, and log analytics tools.
Given that the human brain can only focus on 8-10 items in short-term memory and with all the incoming data from various systems, it’s pretty easy for humans in 2018 to miss things. Manual analysis and health checks are challenges when you have several hundred thousand time-series metrics and a few million log entries to look at post-deployment.
Let AI/Machine Learning Assist Health Checks
At Harness, we don’t just automate the deployment of software artifacts to production; we also automate health checks using AI and ML. We call this Continuous Verification.
We primarily use unsupervised machine learning algorithms like Hidden Markov Models, Symbolic Aggregate Representation, KMeans Clustering, and some Neural Nets to automate the detection of anomalies and regressions from APM and log data.
Within seconds of deploying a new software artifact, Harness can connect to any APM or Log tool and automatically generate a model of application behavior from a performance (response time/throughput) and quality perspective (error/exception/events).
Harness then compares these models with previous deployments and flags any new anomalies or regressions instantly. What takes humans hours to process and analyze takes merely seconds with machine learning algorithms.
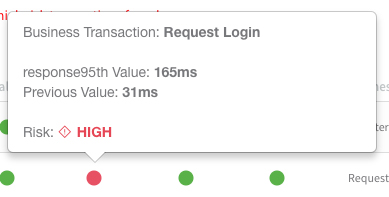
For example, the below screenshots are from Harness verification of AppDynamics APM data:

In the above image, you can see that Harness flagged two business transaction performance regressions post-deployment. Tied to that, the below image shows that one transaction—“Request Login”—actually increased from 31ms to 165ms in response time. All of this analysis is automated with AI/ML.
Here’s another example of Harness detecting error/exception anomalies in application logs from Splunk:
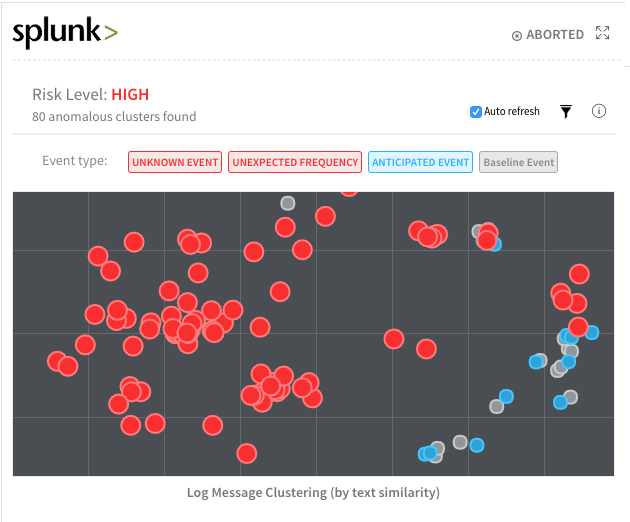
Red dots signify new errors that have been introduced to the application logs from the deployment. Gray and blue dots represent baseline events or error/exceptions that are normally observed with every deployment.
Harness uses KMeans clustering with some Jacard and Cosine distance calculations to generate these visuals. Clicking on any dot also shows the stack trace and root cause of the event.
Automate Rollback with AI/ML Intelligence
Harness can also automate the rollback of deployments using the intelligence from its Continuous Verification. Think of Harness as a safety net that lets Dev/DevOps teams deploy faster but then roll back whenever new anomalies or regressions are encountered.
With upcoming Harness support for PagerDuty, organizations will be able to use PagerDuty as a notification channel as well as a verification source. For example, Harness can query PagerDuty pre-deployment to see if there are any active incidents being experienced in production. The last thing Dev/DevOps teams want to do is deploy to a hot environment.
In summary, Harness offers Continuous Delivery as-a-Service that helps organizations automate the deployment and delivery of software to end users in production. We help customers move fast without breaking things.
Steve Burton is a CI/CD and DevOps Evangelist at Harness.io. Prior to Harness, Steve did Geek stuff at AppDynamics, Moogsoft, and Glassdoor. He started his career as a Java developer back in 2004 at Sapient. When he’s not playing around with tech, he’s normally watching F1 or researching cars on the Internet.

