
- PagerDuty /
- Blog /
- Incident Management & Response /
- Measuring Technical Debt With Incident Management Data
Blog
Measuring Technical Debt With Incident Management Data
by Christopher Tozzi
March 14, 2017
| 6 min read
If technical debt were like monetary debt, it would be hard to keep track of it unless you checked in manually. The only way many people find out their checking account is running out of funds is by logging in and checking the balance — or, worse, having a check bounce or a debit card declined.
But measuring technical debt can be more automatic. That’s because, unlike your bank account, your IT infrastructure can be monitored on an ongoing basis with specialized tools, and you can get notified on critical health metrics. In turn, you can use monitoring data to gain information about technical debt. In other words, you don’t have to do a manual audit to know when something is going awry in your data center. You don’t have to wait for a server to go down before learning about a problem. Incident Management tools provide that information for you. By extension, they also offer a way for you to take stock of your technical debt without having to measure things tediously by hand.
Here’s how incident management can help you keep track of technical debt and correct it, with no additional investment on your part.
Defining Technical Debt
 First, let me explain what I mean by technical debt. Technical debt refers to imperfections in software code or architecture that, over the long term, create inefficiencies or other problems. Even if the imperfection itself is small, it can accrue a lot of “interest” over time as its effects repeat themselves on a continual basis.
First, let me explain what I mean by technical debt. Technical debt refers to imperfections in software code or architecture that, over the long term, create inefficiencies or other problems. Even if the imperfection itself is small, it can accrue a lot of “interest” over time as its effects repeat themselves on a continual basis.
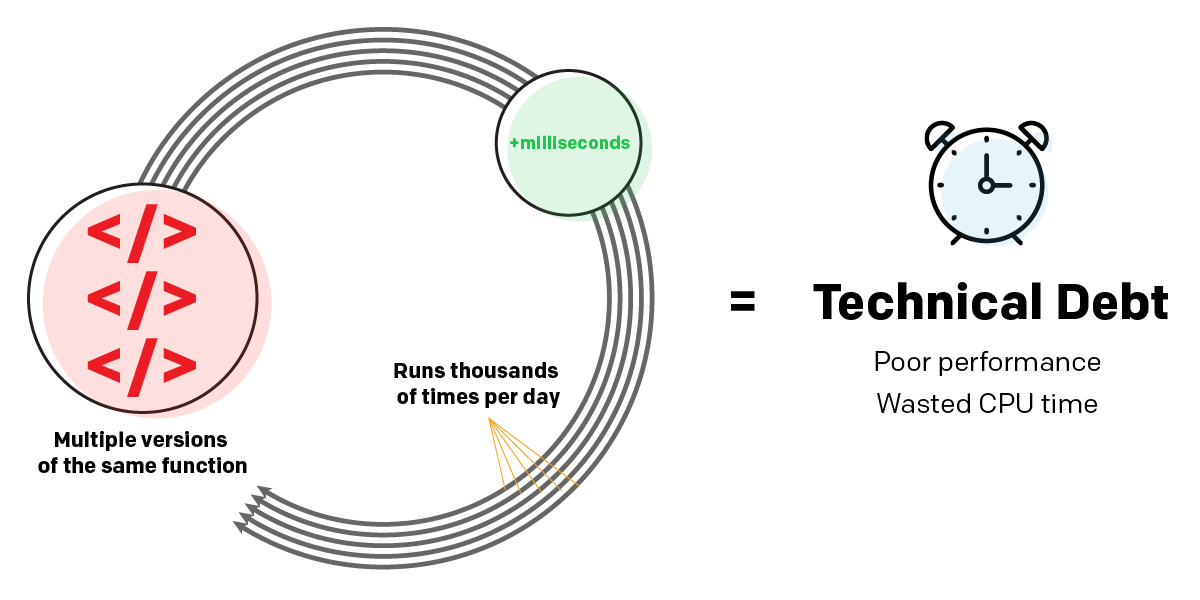
For example, a program whose code contains multiple versions of the same functions, rather than adopting a modular approach, could take a few milliseconds longer to run than a better written program. That’s not a big deal if you execute it once. But if it’s a server-side web application that runs thousands of times a day, the debt adds up quickly in the form of poor performance and wasted CPU time.
Technical debt has lots of potential causes. Sometimes, you might knowingly acquire technical debt because you need to implement something quickly, you don’t have time to follow best practices, and you decide that the debt is worth the cost (at that time at least). Other times, even the nit-pickiest of admins is hard-pressed to avoid technical debt. Unless you could see into the future (for instance, you probably didn’t know that a decade-old switch that you are still using today because you can’t afford to upgrade, would not work well with modern firewall tools). In that case, technical debt is just par for the course of living in an imperfect world.
Tracking Technical Debt
While technical debt has many sources, the nice thing about using incident management to measure it is that this approach makes it easy to track the problems no matter what caused them. Again, instead of doing a time-consuming manual audit of your systems to search for inefficiencies, you can leverage your incident management data as a proxy for assessing the extent of technical debt and honing in on it.
To understand how, let’s take a look at some examples of different types of incident management data that PagerDuty tracks, and what it can reveal about your technical debt.
For starters, take the raw number of alerts that your tools generate. This is a very basic metric, and it can be affected by a number of factors. But assuming that your incident management reporting systems are properly configured and that you make no major change to your infrastructure, there is likely to be a relationship between the size of your technical debt and the number of incidents that your tools report. That’s because more debt means poorer performance, which in turn triggers alerts when response times or resource levels hit certain thresholds. So a steady month-over-month decrease in the occurrence of alerts could mean that your technical debt is declining because your code has become more efficient.
Mean time to resolution (MTTR) is another incident management metric that offers a view into your technical debt. One common cause of poor MTTR is code that is overly complex. For instance, to reuse the example from above, code that was hastily written and contains redundant functions will be hard for an admin to understand quickly. That means a longer resolution time in the event that he has to read and change that code in order to respond to an incident.
The rate of escalations in your incident management data is also a useful measure of technical debt. Escalations occur when the first responder to an incident is not able to solve the problem and has to call in extra help. Frequent escalations likely mean one of two things. First, your admins may not be good at their jobs, but if that’s the case, you would already know about it well before you review your incident management data. The second main cause of escalations is code that is too complex to be handled easily by whoever responds to an incident. If that’s the kind of code your admins are dealing with when they answer alerts, there’s a good chance the code was poorly written and is a source of technical debt.
Finding the Source of Technical Debt
Beyond helping you trace general trends regarding your technical debt, incident management data is also handy for zeroing in on the source of a problem.
For example, if your MTTR for incidents related to a certain program is higher than your average MTTR, there’s a good chance the program in question is generating technical debt. Similarly, if servers running one type of operating system account for a disproportionate number of alerts, there’s probably a code or configuration flaw at play. That’s a technical debt you can address.
The cool thing about using incident management data to locate and address technical debt is that it doesn’t require any significant amount of additional work. You already have monitoring systems in place, along with (hopefully) a central operations and reporting hub like PagerDuty. Taking advantage of these resources to find and fix technical debt doesn’t require additional tools or investment. It helps you proactively make your code and operations more efficient, using the software you already have in place.

