
A Decade of Duty: A Brief Look at PagerDuty’s History
by Alex Solomon
February 21, 2019
| 13 min read
This month is a big month for PagerDuty—we turned 10 on February 18! I never imagined we’d reach this milestone, honestly. A lot of Dutonians have asked me recently: When you first started PagerDuty, did you ever imagine it would become what it is today? My answer is “heck no.” Our original vision when Baskar Puvanathasan, Andrew Miklas, and I started PagerDuty was to build a bootstrapped software company, retire early (when we got to $20k a month in revenue), lay on the beach, and sip on drinks out of coconut shells.
And here we are 10 years later, with more than 500 employees, over $100 million in annual recurring revenue, multiple office locations around the world, and 10,000+ customers globally. We wouldn’t be here without the support of our customers and partners, so thank you all for your encouragement and feedback throughout the years.
The Founding Story
The first rumblings of what became PagerDuty started back in January 2009 in Toronto. Baskar, Andrew, and I all quit our jobs and started working on a startup together. Andrew and I had known each other for many years, as we were in the same class at the University of Waterloo. We both met Baskar while working as software engineers at Amazon.
We spent that first month of ‘09 thinking of ideas and doing research. One of the ways we thought of ideas was by thinking of internal tools that bigger companies had built in-house (like Amazon, where all three of us had worked prior) that other companies of all sizes would need. Baskar thought of being on call at Amazon—it was called being on “pager duty” because back then, you carried a literal pager on your belt.
Engineering teams at Amazon had been following a DevOps methodology for many years. This meant that as a software engineer, you were responsible for writing code, testing it, deploying it to production, and managing and operating your systems in production. Part of that meant being on “pager duty”: When there was an issue, the pager went off, and you were responsible for fixing it ASAP, even in the middle of the night. Amazon had built an internal tool to handle on-call scheduling and alerting via pagers. This tool was bolted on top of their internal ticketing and monitoring systems, so when critical issues were detected, the right people were paged.
After doing a bit of research, we realized that it wasn’t just Amazon that built an internal tool for going on call—Google and Facebook both built their own versions. It seemed like there was a clear need here. We then did some more research and didn’t find any big competitors out there. Also, we found that the domain pagerduty.com was available! The joke I like to tell folks is that if the domain hadn’t been available, I’m not sure the company would exist today.

From left to right: me, Andrew Miklas, and Baskar Puvanathasan.
Creating a Product Out of an Idea
Now that we had our idea, it was time to get to work. On February 18, 2009—10 years ago—we pushed our first commit to GitHub and PagerDuty was born. Over the next several months, we worked furiously to create the first version of PagerDuty.
We launched the initial release of PagerDuty as a beta on Hacker News in August 2009. That beta looked like a skeleton compared what you see in PagerDuty today. The first version of PagerDuty was very much an MVP, or minimum viable product—it didn’t even have services or incidents. Instead of a service, we had alarms that were either on or off, Triggered or Resolved. You’d plug in a monitoring tool like Nagios into an Alarm, and Nagios would trigger the Alarm. (We quickly figured out how limiting the on-off nature of Alarms was for our customers.) Scheduling was also very basic: You could create rotations, but rotations were either weekly or daily. Escalations were limited to three levels—primary, secondary, and tertiary.
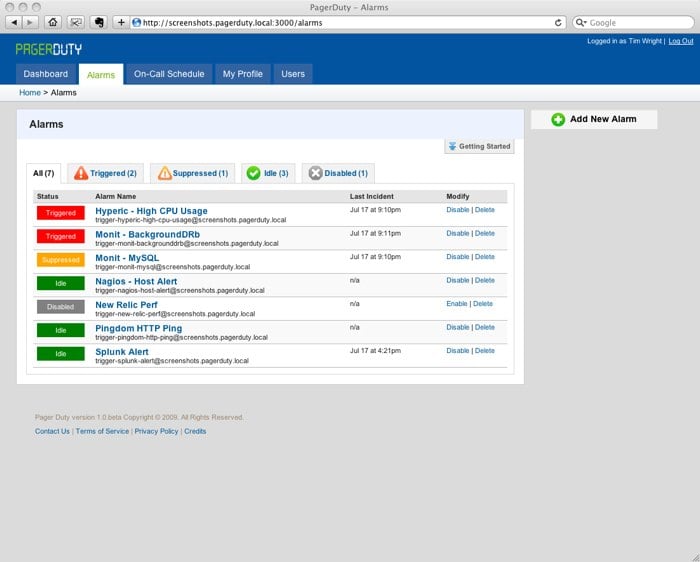
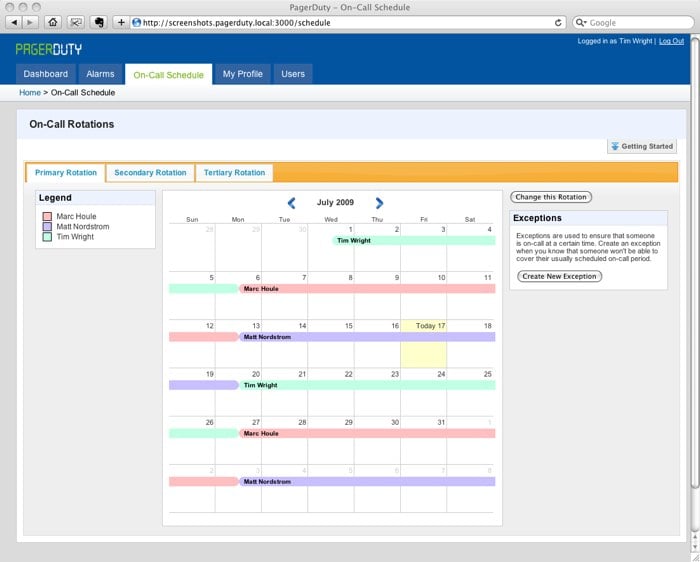
What PagerDuty used to look like.
We aimed to launch as quickly as possible in order to get the product in the hands of users so we could learn. So we took some shortcuts in the process: We built the application as a monolithic Ruby on Rails app, we didn’t write any unit tests, and we didn’t do code reviews. Plus, the first version of our schedules didn’t account for Daylight Savings Time, which we were well aware of; we figured we’d fix it before the DST flip occurred in the fall. We figured that if we were successful with the product, we could fix all of these problems later—and we did!
After the beta launch, we got our first batch of beta users and started iterating on the product based on their feedback. Then, in December 2009, we launched the paid version of the product. We built our pricing based on both the number of users and the number of alerts, with our most expensive plan being $299 a month for 25 users.
Then, in 2010, we applied to Y Combinator, the prestigious startup incubator that had invested in lots of amazing companies like Dropbox, Airbnb, and Stripe. We got into YC for the Summer 2010 batch and moved the company (aka, the three founders) from Toronto to San Francisco. Starting that May, PagerDuty’s “offices” were based out an apartment off of El Camino Real in Mountain View. We had no furniture other than desks, beds, and a bright pink lamp that is still in our San Francisco office next to my desk.

For us, going the Y Combinator route was less about product advice as we were already launched and had paying customers when we went through the program. Instead, YC was a bootcamp for fundraising. Andrew, Baskar, and I came from an engineering background and didn’t know anything about the world of investors. YC and Paul Graham helped us hone our investor pitch and pushed us to create a long-term vision for the product. They taught us about the world of fundraising and made lots of introductions to investors. After YC’s Demo Day, we started fundraising and successfully raised a seed round of $1.9 million from a bunch of amazing angel investors, including SV Angel, Steve Anderson, and Michael Dearing.
Business Model Takes Shape, First Signs of Growth
In 2011, we started hiring, growing the company from 3 founders to 11 employees, almost all of whom were engineers. Our sales model was fairly straightforward at that time: Customers would go to our website and learn about the product. They’d then sign up for a free trial, eventually use a credit card to pay for their service, and that would be that. We didn’t really have a salesperson and we thought that would be fine—we assumed our customers were all engineers who were just like us and didn’t really want to talk to people either.
However, we quickly figured out that not all of our customers were like us—some of them wanted to talk to someone, ask questions, or pay by purchase order instead of entering a credit card number. At this point we didn’t have anyone doing sales full time, so I did it myself, mostly over email.
We quickly learned that we were onto something. We were solving a real hair-on-fire problem with our on-call management and alerting solution. The primary value proposition for users and customers was ensuring that every single issue or incident that happened in a critical system or application was handled quickly by the right person and that nothing fell through the cracks.
We also learned of a second value prop, which was centered around improving the quality of life for the folks who go on call. Before PagerDuty, there was chaos: alerts would go to everyone on the team simultaneously, which meant everyone was on call all the time, which meant some folks would step up and become heroes while others would shy away and let others bear the brunt of incident response. PagerDuty brought process and ownership to being on call: Folks knew when they were on call and were ready to respond to pages—and, just as important, knew when they were off call and could leave their laptops at home and live life as normal.
One of our main drivers for acquiring customers in those early days was word of mouth. (It continues to be a major driver today.) Folks in the DevOps community were (and still are) very vocal about better ways to do things, and that included tools and products that solve real problems. Our users talked about PagerDuty at conferences; we were mentioned in conference talks, as well as in the “hallway track.” Our users also mentioned us over social media, and many of our users, when switching companies, would sign up their new employer for a PD account while leaving PD behind at their previous company.
That Time When We Had to Convince People PagerDuty Was Real
Our number of employees doubled in 2012. I was doing more and more sales, and it was clear we needed someone to drive that forward. We hired our first two sales people, and they became integral to the success of the company. We saw bigger and bigger contracts coming through and started generating some good buzz. We quickly hit over 1,000 customers and realized that we had a very clear product-market fit.
We weren’t the only ones who realized it: Our plucky startup was starting to get real attention from not just customers, but also investors.
We decided to capitalize on what we thought was a once-in-a-lifetime opportunity to create a new category in the market. We decided it was time to raise a Series A funding round and started meeting with investors. At the same time, we hit a major milestone: $3 million in ARR and over 2,000 customers. To celebrate this, we took our entire team to Napa Valley for a day of wine tasting.
Unfortunately, on the same exact day as the celebration, Andrew, Baskar, and I were meeting with investors at our office to pitch them on PagerDuty. The office was completely deserted and we had our work cut out for us convincing a particular venture capitalist that we were indeed a “real” company and that we did have employees who were just all out of the office on that one day.

Furiously signing term sheets in a mostly empty office.
We ended up having term sheets from six or seven different venture capitalists and signed our Series A funding round with one of the best VCs in the world, Andreessen Horowitz.
Building Up Steam
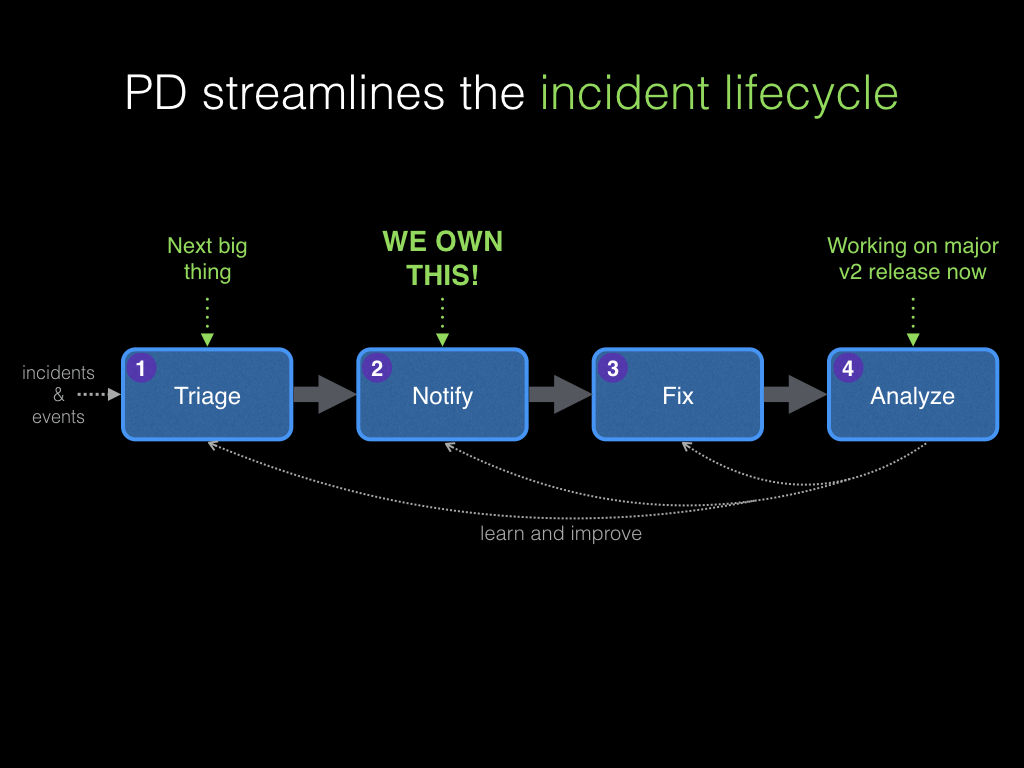
In 2013, our company grew from 20 to 60 people, and we built out our initial executive team. In the summer of 2014, we hit another big milestone—$10 million in annual recurring revenue. Around this time, we really started crystalizing our incident management vision: the process of Triage > Notify > Fix > Analyze.
We clarified that triage is all about event management, noise reduction, and automatic clustering of related events and alerts, a process that incorporates machine learning. Notify is centered around workflow, looping in both on-call responders, as well as stakeholders who need to be informed about incidents and outages. Fix is about collaboration, war rooms, and automating the fix. Analyze is about supporting blameless postmortems and providing analytics to measure the performance of your systems as well as your people.
But it wasn’t all smooth sailing. Early on, we learned some lessons the hard way. For example, we hired an engineer who was brilliant, but very negative; more so than that healthy dose of engineering pessimism. Inevitably, it blew up and this person left, taking two other people with them.
After this, we became intentional about our culture. In 2015, we started designing our first set of cultural values, which encompassed who we were and what we believed in. We decided that it was imperative that we not be exclusively focused on “success at all costs”—that, for us, it was more important to go about things the right way and building the company that we really wanted to work at long term. These cultural values persist today. We use them in hiring, in how we manage people, and throughout our performance review process.

Cultural values: 2015.

Cultural values: 2019.
Bringing Jennifer on Board
In 2016, we had scaled the company to over $50 million in ARR and 200 people. Increasingly, my time as CEO was spent focused internally, on hiring and managing the team. I wasn’t spending much time talking to customers and found that I didn’t have enough time to focus on the product side of things.
After much deliberation and research, as well as speaking with other founders who had been in my shoes, I came to the conclusion that I needed to replace myself as CEO. We started a very deliberate search process, working closely with our advisors, investors, and our board of directors. Our focus was to find someone who would propel PagerDuty to the next level, inspire our colleagues to bring their best, and embody our cultural values. It was a huge decision, ultimately the biggest decision in the history of our company.
A couple of months into the search process, I met Jennifer Tejada and spent over 40 hours with her doing formal interviews, as well as having lunch / dinner / drinks and really getting to know her. Jennifer was truly a unicorn candidate: She is someone who is world-class in multiple categories. She is a visionary, and an inspirational leader with strong product acumen and a solid marketing background (both in consumer products and B2B software). Just as important, she fit the PagerDuty mold in terms of being humble, hungry, and deeply passionate about building a long-term company with a culture that puts people first, whether they be customers or employees.
Jennifer took over the reins in the summer of 2016. I can truly say that hiring her was one of the best decisions we’ve made. Over the past two-and-a-half years, she’s built an amazing team, made inclusion and diversity one of our top priorities, and scaled PagerDuty to grow even faster—to over $100 million in ARR and more than 500 employees.

Jennifer and I receiving Entrepreneur of the Year awards from Ernst & Young. June 2018.
Achieving the Vision
2018 was an amazing year for PagerDuty: We realized our vision of becoming a digital operations platform. A decade ago, we started out as an on-call management and alerting tool. Over the years, we expanded to address the full incident lifecycle (Triage -> Notify -> Fix -> Learn). Then, over the last couple of years, we became a real-time operations platform. As part of our “platformization,” we introduced several new products:
- Modern Incident Response enables teams to resolve critical incidents faster and prevent future recurrences through end-to-end response automation, integrations with ITSM toolchains, and easy postmortems.
- Event Intelligence collects signals from multiple tools and correlates actionable alerts while suppressing noise, empowering responders to focus on solving incidents quickly.
- Visibility provides real-time insight into the business impact of incidents, and connects technical and business responders to drive proactive business response to minimize customer impact.
- Analytics combines machine and human response data collected over time to provide business and technical leaders with operational insights so they can drive better business outcomes.
This is just the beginning: I can’t to see what the next 10 years has in store. Thank you again to everyone who has joined us on this wild ride!

