- PagerDuty /
- Blog /
- Best Practices & Insights /
- 3x in 3 years: Scaling an Engineering Organization
Blog
3x in 3 years: Scaling an Engineering Organization
by Roman Shekhtmeyster
July 27, 2017
| 13 min read
Three years ago, I joined an up-and-coming startup called PagerDuty as an Engineering Manager. Having received Series A funding in 2013, the company was in hyper-growth mode and hiring aggressively across all areas. The Engineering team was less than 30 people at the time, and a big draw for me was (and still is) learning about the structural challenges facing a rapid-growth organization. As we approach 100 Dutonians in Engineering, it seems appropriate to look back and reflect on the changes so far.
Evolution of organizational structures is a fascinating process—full of mistakes, dead ends, reinvented wheels, and hopefully, lessons learned. There’s plenty of literature covering engineering organizations, much of it boiling down to either abstract lists of pros and cons or to blog posts that sing praises of whatever process the company happened to adopt at the time of writing. I want to take a different approach and examine the historical reasons that pushed our engineering team to continuously experiment with and evolve our structure, with all of the accompanying missteps and learnings.
Note: Some of the events and details have been simplified for the sake of the narrative—many of these are worthy of posts of their own. Bookmark this blog to keep an eye out for new content.
The Siloed Organization
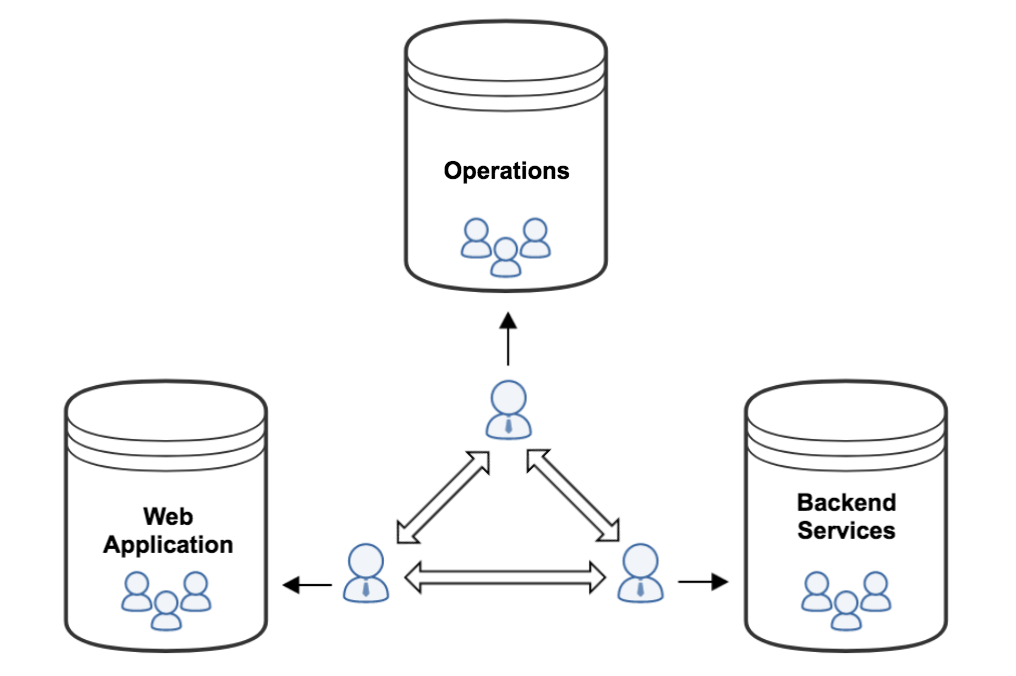
PagerDuty circa early 2014 looked something like this:
- The Engineering organization was split between the San Francisco and Toronto offices.
- The Operations team was responsible for infrastructure automation, security, and persistence (SF only).
- The Web Application Team was responsible for the customer-facing aspects of PagerDuty (SF only) and developed primarily with Ruby on Rails and MySQL.
- The Backend Services Group was responsible for reliable data ingestion and notification delivery (split into co-located teams in SF and Toronto) and developed primarily with Scala and Cassandra.
- There was only a partial adherence to DevOps—the Operations team went on-call for infrastructure monitoring alerts, other teams on-call for the code they deployed.
As Engineering grew from a small handful of people to several, distributed teams in very short order, the product development process remained rather immature. Despite superficial trappings of agility with stand-ups and sprints, we were essentially using the Waterfall model. Leadership defined the projects to work on, assigned the individual engineers to those projects, and set the target delivery dates. Predictably, the dates were rarely hit and the project-tracking spreadsheets were in a perpetual state of disrepair and, eventually, disuse.
Things didn’t look much better on the ground. Product managers kicked off new projects by drafting lengthy functional design specifications, doing their best to anticipate any possible questions that might arise—a consequence of Product and Engineering not actually interacting very much during development! The spec was presented to the Web Application and Backend Services teams, who then worked on the user-facing and backend aspects independently. New infrastructure requests had to be made to the Operations team weeks in advance.
Integrating all of these separate efforts into a coherent feature release was a nightmare. We had missing or incomplete infrastructure, hot potato bugs, functionality gaps (each team thinks the other is taking care of it), lack of ownership or empowerment for both engineers and product folks, missed dates, and organizational silos. The desire to hit dates caused us to take fewer risks, and we became more conservative in our implementations as well as averse to adjusting the product specs.
This combination of departmental structure and development processes pushed the topic of siloing to the forefront of every other discussion within Engineering that year. And boy, did we have silos:
- Web Application vs Backend Services. There was palpable tension between the two groups. Neither really understood what the other group was working on, and both were frustrated.
- Ruby vs Scala. Similar lines of conflict to the above, with much bikeshedding and identity building around specific languages.
- Operations vs Development Teams. Both sides were frustrated with the Ops Team being a bottleneck for all server provisioning. Operations also experienced a lot of pressure from looming deadlines.
- San Francisco vs Toronto. With every team geographically co-located, a distinct “them vs us” vibe developed between the engineers in the two locations. Both sides found something to grumble about.
The rigidly defined sets of responsibilities did not leave teams a whole lot of room for cross-functional collaboration. We experimented briefly with a concept of “working groups”—small, temporary, diverse squads drawing folks from the existing teams with the intent of working on scoped, timeboxed, cross-cutting projects. These ended up introducing more chaos by destabilizing the primary teams, and so the experiment was abandoned.
Still, the need to collaborate and deliver with better consistency and predictability was of utmost importance. Everyone was sick of siloing, so that had to go. We had our work cut out for us.
The Matrix Organization
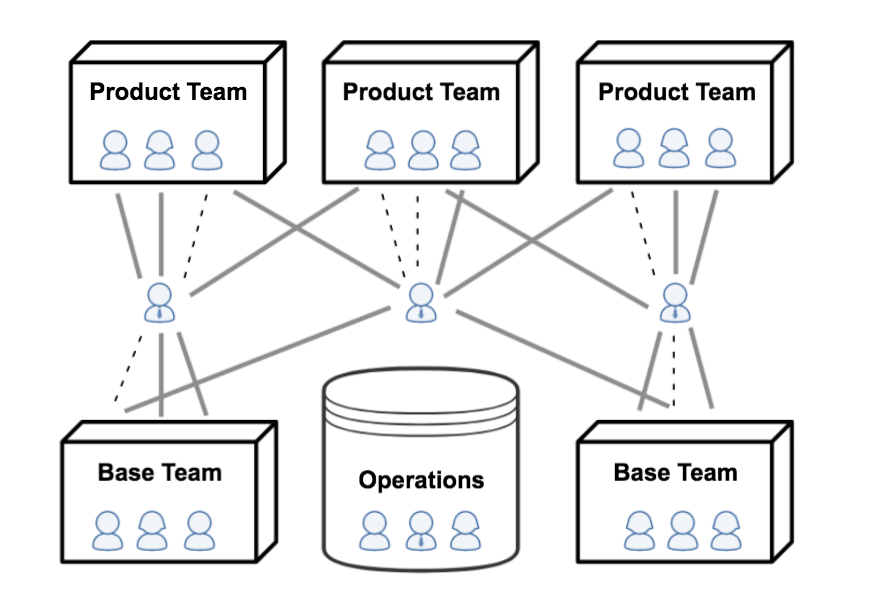 By early 2015, dissatisfaction with the state of things as well as rising interest in Agile methodologies reached critical mass and resulted in a departmental shake-up. Several new teams were formed that aligned around specific product directions. They followed the Scrum process and consisted of engineers from both Web Application and Backend Services teams, as well as product owners, Scrum Masters, and UX designers.
By early 2015, dissatisfaction with the state of things as well as rising interest in Agile methodologies reached critical mass and resulted in a departmental shake-up. Several new teams were formed that aligned around specific product directions. They followed the Scrum process and consisted of engineers from both Web Application and Backend Services teams, as well as product owners, Scrum Masters, and UX designers.
Given the less than ideal pace of progress made on the product in the prior year, the new teams were optimized for product delivery. To ensure that they could spend 100 percent of their time on cranking out new features, maintenance work was delegated to the Backend Services teams. These became known as “base teams” as they adopted Kanban methodology and took on ownership for all of the services in production, including all product on-call responsibilities. Furthermore, base teams fed into the product teams—engineers migrated from one to the other as product work ramped up.
These were obviously big changes. In an effort to minimize the impact of team shuffling on individual engineers (and to postpone having to deal with remote reports), the reporting relationships were not touched. This of course complicated everyone’s life tremendously, because now we had a dual reporting structure, aka the matrix organization! Many engineers ended up on teams that were not assigned to their direct supervisor and managers were now playing the roles of “people manager” (responsible for people, some of whom were on other teams) and “functional manager” (responsible for teams, where some engineers reported elsewhere).
The good news was that the old silos were mostly smashed, never to be seen again. Web Application Engineers working in close proximity with Backend Services Engineers were able to see past each other’s differences and move towards shared goals. Most teams were now geographically distributed as well, which worked wonders in bringing the two offices together.
The bad news was that a slew of new problems was introduced:
- It was very difficult to rally a team around technical maintenance. Base teams struggled with forming long-term roadmaps and coming to terms with operational ownership of all production services.
- The feeder model had a very real impact on team cohesion. Turns out that changing team composition over and over is not so good for morale.
- Dual reporting structure created a ton of inefficiencies.There was a lack of visibility into the day-to-day activities of a direct report, additional communication overhead between people managers and functional managers, and general confusion around responsibilities.
- We adopted Agile processes, rather than agility. Scrum certainly helped with overspecification, integration, and product owner involvement. However, our approach to software delivery did not change—feature releases were still big bang affairs that delivered questionable value.
- More teams meant more load on the Operations folks. With frequent infrastructure requests and additional on-call responsibilities for each new service, clearly, this approach did not scale.
All things considered, we were still in a much better shape than a year ago. But there was still a long way to go.
The Agile Organization
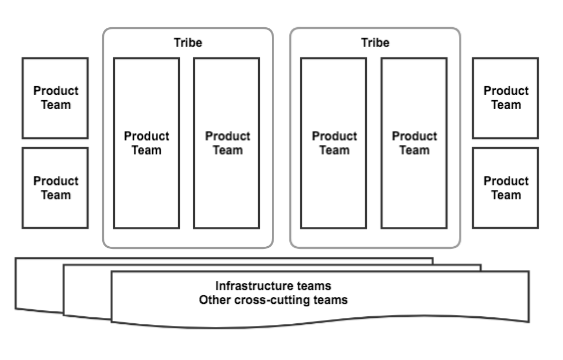 After living with the new organizational structure for a year, we accumulated quite a lot of learnings. Agile was good (but we did not do enough of it), DevOps was good (but we did not do enough of it), matrix management was not so good (and we’d had enough of it).
After living with the new organizational structure for a year, we accumulated quite a lot of learnings. Agile was good (but we did not do enough of it), DevOps was good (but we did not do enough of it), matrix management was not so good (and we’d had enough of it).
In early 2016 we restructured once again. “Vertical” product Scrum teams were now responsible for particular slices of the product. “Horizontal” teams were responsible for cross-cutting product or infrastructure concerns, and were tasked with setting best practices and enabling other teams to move fast. Product delivery teams owned their roadmap, requirement definition, implementation, deployment, and maintenance of their code and infrastructure (!) in production. We had adopted a true DevOps “you code it, you own it” approach.
How did this solve our previous concerns?
- No more maintenance teams. Each team owned a portion of the product or infrastructure and was empowered to move quickly and innovate.
- No more feeder teams. Headcount was opened for specific teams.
- No more dual reporting! As an organization, we got a lot more comfortable with hiring and managing remote engineers. With physical distance no longer an impediment, we were able to assign managers to teams without any dotted line relationships.
- We’re focused on getting stuff done. The mantra of GSD (Get Sh*t Done) has been permeating our collective consciousness, challenging the teams to introspect and shed the legacy of overspecification and over-engineering in order to grow into pragmatic, productive, agile delivery machines.
- Self-service enabled growth. The Operations Team did a lot of work to empower the product delivery teams, including providing fancy ChatOps tools to self-serve for all sorts of infrastructure needs. This was key to embracing DevOps all the way and moving infrastructure alerts out of Ops and into the relevant teams owning the actual hosts (who could resolve issues faster anyways).
The subject of GSD is worth digging into a bit more. Through practice, we got more and more comfortable with the ideas of team autonomy, innovation over invention, and business bringing problems to solve rather than solutions to implement. It’s not easy to let go of the idea that we know what’s best for the customers. A laser focus on delivering the minimum viable product, and seeking immediate feedback and incorporating it in during the development cycle, was key. It allowed us to iterate quickly, maximize value, minimize gold plating, and shorten the time to get a prototype into the customer hands from months to days or weeks. In other words, we transformed from an organization that “follows agile processes” to an actual agile organization.
As the number of product delivery teams grew, an interesting phenomenon developed—we saw an emergence of the so-called “tribes” (hat tip to Spotify’s team model); i.e., groups of teams related to each other by common functionality or common mission. These arrangements have resulted in benefits such as shared ownership, shared knowledge, shared roadmap (separate from individual team backlogs), and shared vision. Tribal organization is something we are still experimenting with—stay tuned for future updates on our learnings with tribes.
We’ve been running with this structure for 16 months now and it just works. Certainly teams and associated ownership lines will evolve as the company continues to grow at a fast pace, and some details will change as we continue to invest in improving ourselves. At the same time, it’s clear that we have done enough of the wrong things to learn what the right thing should look like.
Lessons Learned
As I think back to some of the decisions that were made early on and some of the awkward intermediate states that our organization has endured, I’m tempted to smack myself in the head and ask why it didn’t occur to us to jump to the obviously superior end state. The reality, of course, is never that simple—those decisions were a function of our state, our priorities, our people, and our challenges at the time. You may have recognized some of your own challenges as well, in which case I hope you’re able to take something away from our experience.
If I had to do it all over again, these are the learnings I would bring with me:
- Minimize dependencies between teams. Dependencies lead to blocking, bugs, misunderstandings and bad feelings. Empower teams to deliver without waiting on others and you will see major productivity improvements.
- Minimize changes to team composition. Business realities dictate that occasionally resources need to be shifted from one place to another. Think long and hard before moving folks around, as it can seriously impact team morale and productivity.
- Do not overly prescribe team ownership and responsibilities. Flexibility here leads to longer-term wins. Encourage teams to solve their own problems and you will have less problems with the previous two points.
- Do not be afraid of continuous learning and experimentation. This applies to everything—code, process, organization. One does not get better by doing the same things over and over.
- Agile processes are nice; agile culture is better. Standups and sprint reviews don’t bring a whole lot of value on their own. Focusing on minimum viable product, rapid feedback loops, and collaboration requires a cultural change, but it maximizes the customer value delivered.
- Operational ownership of code should live with the teams. It is the best way to balance system reliability, code quality, and organizational scalability.
- Cross-functional, full-stack teams are best for product delivery. This is very much in line with the dependency minimization point above. Each team should be able to go from requirements gathering to deployment without needing to involve outside experts or project handovers. Specialist teams do have a place, but more in the realm of the “horizontal” teams discussed earlier.
- Hire generalists that can work in any environment. Teammates should not attach their sense of identity to specific tools, frameworks and stacks as technologies and technical directions change. The people best positioned to thrive in a high-growth environment are those that focus on learning and using the right tool for the job. Consequently, be ready to provide those learning and growth opportunities.
- Avoid matrix management if you can help it. Consider if there are other ways to address the problems that dual reporting may appear to solve.
- Embrace distributed teams. Building cohesive teams with remote members is not without challenges, but the benefits are many. Martin Fowler pointed out that, “by making a team remote, you can widen your range of people you can bring to the team. A remote team may be less productive than that same team if it were co-located, but may still be more productive than the best co-located team you can form.” In other words, allowing for remote members creates a much larger hiring pool, so you can build a stronger overall team.
As organizations grow and mature, there is a tendency to slow down, calcify, and become more conservative. Through practicing continuous improvement and evolving our practices, we’ve managed to buck the trend and grow more agile, pragmatic, and productive with time — and you can do the same.
Here’s to three (and many) more years of learning!