
How to Standardize Service Ownership at Scale for Improved Incident Response
by Hannah Culver
June 22, 2022
| 8 min read
Service ownership is a DevOps best practice where team members take responsibility for supporting the software they deliver at every stage of the development lifecycle. This level of ownership brings development teams much closer to their customers, the business, and the value being delivered.
Service owners are the subject matter experts (SMEs) for their services – and in a service ownership model, they are also responsible for responding to any production issues. For teams moving to this model, going on call can seem daunting. Maybe you’ve heard horror stories about weekends and evenings spent holding your laptop and responding to incidents?
There’s no way to sugarcoat it: being on-call is tough. But best practices like service ownership can introduce more structure and predictability to an on-call shift so that, ideally, there is a net quality of life improvement for everyone.
Why is service ownership important?
Imagine this scenario: you’re called into a meeting because something is wrong somewhere in the system, but since you don’t have service owners determined, nobody knows who the SME is. Fifteen minutes turns to 20, and then 30, and so on. Meanwhile, more people are jumping on the call, yet making no progress.
This type of chaotic incident response wastes precious time – it’s the epitome of inefficiency. And the worst part is that it still happens all the time.
It doesn’t have to be this way. But first, let’s examine why so many teams are burdened by manual incident response that drags out forever. When you look at the reasons for the slow down, it boils down to teams not being able to answer a few very important questions:
- What services are impacted?
- Who owns those services?
- What are these services’ dependencies – and who owns those services?
Meetings like the example above attempt to answer these questions, but in a reactive manner. Until teams can answer these questions, they are at a stand still and cannot make progress on resolving the incident.
This is becoming more and more common as the technology ecosystem continues to change and grow more complex at companies of all sizes. Hundreds of services, microservices, and distributed ownership make it hard to know how to take action when something goes wrong.
Service ownership can help organizations become more proactive about incident response. Nevertheless, this is no walk in the park. Cultural change is hard, and even the most successful organizations which have managed the shift to DevOps and service ownership would agree that following best practices, and having a process for adopting service ownership, can help with stickiness and drive scale across the entire organization.
When organizations are able to adopt service ownership, everyone—from service owners, to executive stakeholders, to customers—benefits. Service owners are only called in when necessary. Stakeholders know what’s affected by an incident, and can work with the technical team to mitigate impact. And customers will encounter a shorter service disruption with clearer communication throughout.
In a world where customer expectations have never been higher, and customer experience is key, this can put your organization above the competition – all while making life better for the people who respond to the incident.
But what actually is a service?
Defining a service can be trickier than it may seem at first glance. We’ve seen organizations split services many ways, and it’s not always as simple as matching services to what’s deployed in the cloud. For some organizations, there’s a monolith that needs to be taken into account as well. So how can you determine how to break things up into manageable pieces for which a team can be responsible?
At PagerDuty, we define a service as “a discrete piece of functionality that provides value and that is wholly owned by a team.” Another way to think of it is that a service represents an entity you monitor, and serves as a container for related incidents that associates the incidents with the right escalation policies.
In short, it breaks down like this: if you monitor it, and you want incidents to be associated with it, and you want certain people to be on call for it, then it’s a service. This is a broader definition that allows more flexibility in how teams might define unconventional services.
However, responders need to know more than just these boundaries to be fully prepared to deal with issues. This is where service configuration can make a big difference.
What makes a service well-configured?
At PagerDuty, we’ve established a set of standards that we feel are valuable to organizations looking to further their service ownership journey. These act as guidelines for how we create our services, and determine what “good” looks like.
They’re flexible as well. Not every service is built the same, and some of our standards may not apply in each circumstance. Think of them as a jumping off point that our customers can use to make on-call be more efficient and less painful to their first-line responders.
It’s important to note that each organization will ramp differently, and that service ownership is a process, not a single box to be checked off a to-do list. Depending on your operational maturity, you may need to set and adopt standards at a different pace.
If you’re relatively small and new to service ownership, with only a handful of mostly cloud-based services, you may be able to set standards and configure your services accordingly in a few days. If you’re starting from scratch, it’s even easier: you can apply these standards when you create your very first services, setting you up for long-term success without needing to go back and make changes to previously configured services.
But if you’re a larger organization with hundreds or even thousands of services, this might be a tougher shift. For these organizations, here’s a few questions to ask that can help you think about how to move forward:
- What subsets of existing services could you set standards for today, and what are those standards? You may find that some standards are easy to apply to all your services. For example, services should have a name that accurately describes what it does. If there are standards like this that you know the majority of services should follow, then that’s a good place to start implementing. Think about how you could ask pilot teams to make these changes.
- What does the process for creating net new services look like? You may have your standards determined, but changing all your current services to meet these standards is a difficult undertaking. If you’re a larger organization, it’s not usually feasible to reconfigure all services at once – and reconfiguring services can be more frustrating than following a process to set them up correctly in the first place.
- What is your long-term goal, and what does a timeline look like for that? Some services may not need these standards, and that’s okay. Make a plan for the rest of the services with a deadline, then start onboarding additional teams to the process, making small, incremental changes over time.
- How do we know our dependencies? Beyond creating and applying standards, it’s also important to know how your services map to each other and affect one another. While establishing standards, think about how you can encourage codifying this information during the configuration process.
Individually, answering these questions may not seem like big differentiators – but when you think about how they scale, they make a big difference for how well you respond to incidents.
How does this help incident response?
During incident response, it’s important that you don’t waste time or energy on work that doesn’t matter. Everything must be pared down to what the team needs to focus on to resolve the incident.
Service ownership helps you gain that clarity throughout the response process:
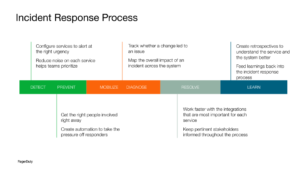
For instance, if you’ve configured your service well, you’ll be alerted with the correct urgency and minimal alert noise, allowing you to respond to only the most important signals and prioritize accordingly. You’ll also be able to get the right people on the scene quickly, since you’ll know who the service owners are. As you grow in maturity, you’ll also be able to create automation sequences for your services that help you reduce the work required to return service to normal.
Diagnosing what went wrong is also easier, as you’ll see what changed on the service. And with service mapping, you can understand the overall impact to the system.
During resolution, you can work faster with the integrations that your service needs, as well as keep stakeholders informed. You can streamline communication to only those people who you know will be affected by your incident, keeping the impact to a minimum even within the organization.
Lastly, you’ll learn from incidents better. As the SMEs for your service, you’ll gain historical context, and feed those learnings back into your response process, making you more resilient over time.
As you scale service ownership across the organization, these improvements make a drastic difference to both customers and teammates. If you’re looking to adopt service ownership or improve your operational maturity, and want a partner that can guide you through the process, try PagerDuty for free for 14 days. If you’d like to learn more about standardizing service ownership at scale, check out this webinar.

