- PagerDuty /
- Blog /
- Best Practices & Insights /
- Supercharging incident response with runbook automation
Blog
Supercharging incident response with runbook automation
by PagerDuty
August 10, 2021
| 4 min read
The global pandemic is estimated to have accelerated digital transformation by at least seven years—and it’s showing no signs of stopping. In fact, companies are investing even more into software-driven experiences. A recent Gartner forecast points to worldwide IT spending increasing 8.4% to $4.1 trillion in 2021, with much of that spend on mission-critical, customer-facing services.
The key takeaway is that online revenue and competition have never been greater, and an organization’s digital services have to be available around the clock. Experience is everything and uptime is money. However, digital incidents are inevitable. So, how quickly companies can fix an issue and minimize impact on both the bottom line and the customer experience becomes the key differentiator.
Today, many ITOps and DevOps teams are still reliant on manual and reactive incident response processes. But as IT environments continue to grow in complexity, this approach is no longer sustainable. Teams need a way to streamline incident response and keep services always on, and that way is through automation.
Taking a Modern Incident Response Approach
Relying on manual and reactive incident response increases mean-time-to-acknowledge and resolve (MTTA/MTTR) and wastes precious people hours. Historically, the approach has been to swarm the problem with more responders, which often ends up with dozens, if not hundreds of team members on an all-hands call. This happens because responders are not armed with the information they need to act when an incident occurs. They need to be able to answer a series of questions quickly to get to the bottom of an incident and fix it. Questions like, what changed in the environment? Who owns this service? And what signals hold the clues?
In any organization, there are tools, scripts, and manual commands teams use to answer these questions. However, these workflows often only exist in the heads of a few subject matter experts, or require manual intervention to execute. Equally, where IT Service Management (ITSM) solutions have played a role in managing non-urgent, queued work, these tools are not built for the urgent, real-time work of an always-on world.
These traditional approaches are representative of organizations who are yet to mature their approach to digital operations. The good news for leaders charged with protecting experiences and the bottom line, is that there is a way to change the narrative and accelerate operational maturity: Runbook Automation.
The Path to Shorter Incidents and Fewer Escalations
Runbook Automation is the process of documenting all the aforementioned scripts, tools, API calls, or written manual procedures, into Runbooks. These are the methods teams use to complete repetitive tasks and resolve incidents—such as restart servers, copy artifacts, manipulate files, etc. Runbook Automation standardizes incident response by capturing and automating these methods and allowing them to be delegated and executed by anyone.
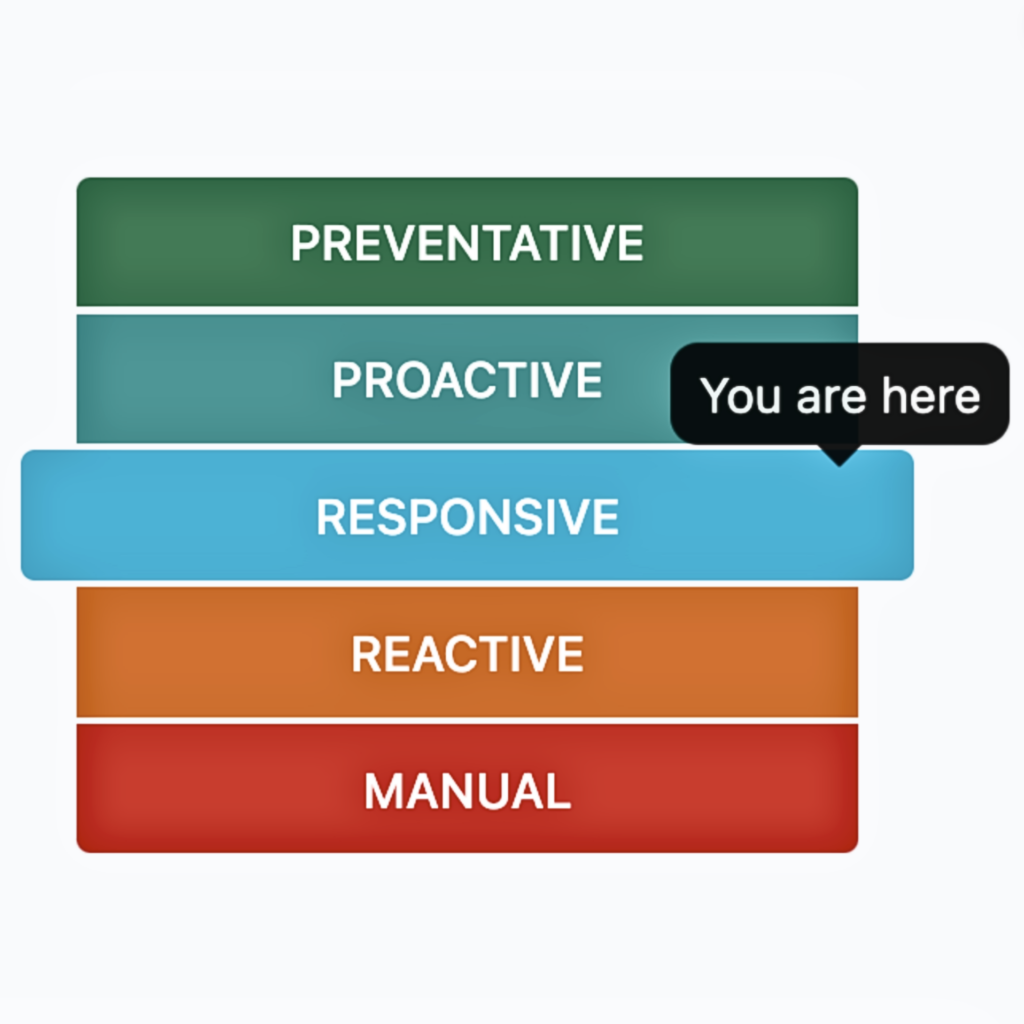
With Runbook Automation, responders can run automated workflows for diagnostic and remediation activities. By directly resolving known issues, they reduce the volume of incidents that get escalated while significantly speeding up resolution. But to realize these benefits—and mature from a reactive to preventative approach—requires cultural and platform change. As the image shows (fig.1), achieving digital operations maturity to enable Runbook Automation is a multi-stage evolution.
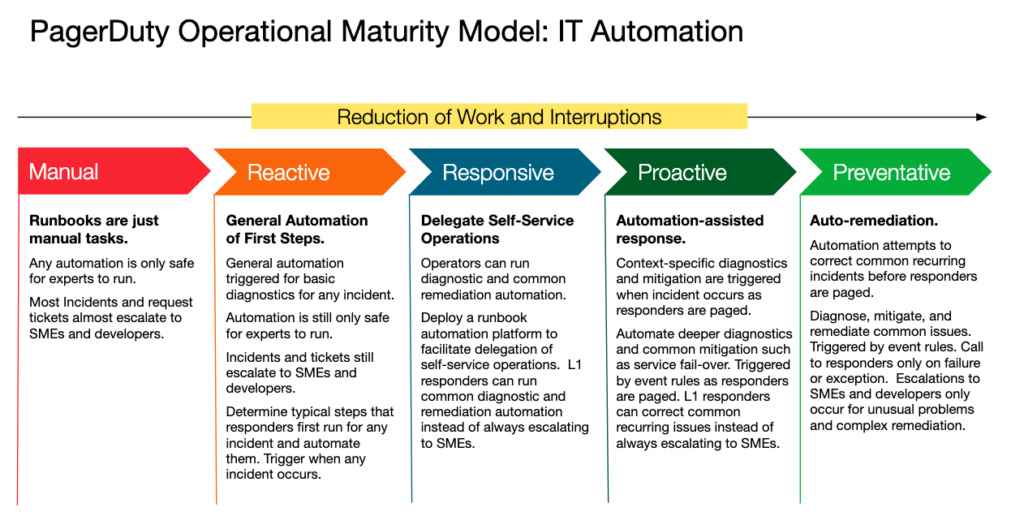
fig. 1
To evolve successfully, organizations should start small so they can improve the capacity for automation as they learn and realize more benefits. It requires a progressive “crawl, walk, run” approach (fig.2).
- Crawl: Automate simple, single-step actions with no impact on service performance or availability, and that require little processing.
- Walk: Automate multi-step sequences that provide deeper diagnoses and remediate many common or even recurring problems.
- Run: Automate complex actions that can significantly impact performance or availability and typically involve privileged access for many steps between multiple systems.
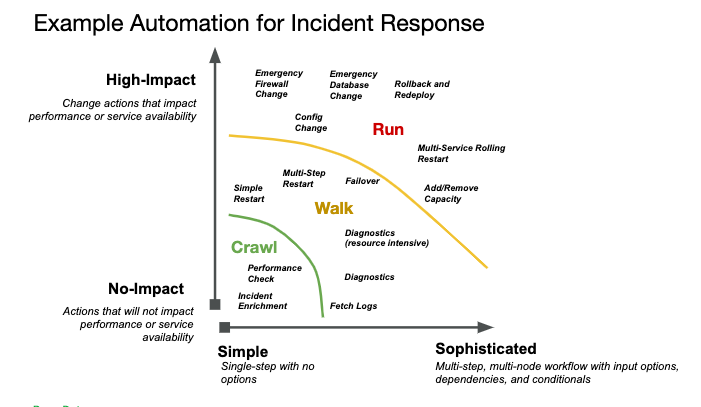
fig. 2
We help organizations along this path with our Rundeck by PagerDuty solution. Rundeck augments existing incident response with Runbook Automation. It makes existing automation, scripts, and commands more secure, auditable, and easier to run. With Rundeck as a central hub executed through PagerDuty, tools and infrastructure can be connected and tasks needed for incident resolution can be safely delegated to responders via self-service.
The Combined Power of Rundeck and PagerDuty
Using Rundeck and PagerDuty together offers organizations a powerful way to further improve MTTA and MTTR, protect revenue, increase operational productivity, and reduce burnout. The combined power of the two enables incidents to be resolved within minutes (fig.3). If you want to read more about how to get started with Runbook Automation, download our new eBook here.
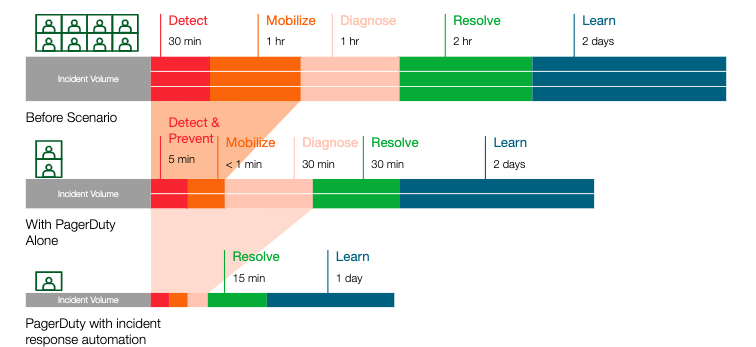
fig 3.
To learn more about Rundeck by PagerDuty and to schedule a demo, visit: https://www.rundeck.com/see-demo.