
- PagerDuty /
- Blog /
- Digital Operations /
- 10 questions teams should be asking for faster incident response
Blog
10 questions teams should be asking for faster incident response
by Hannah Culver
September 13, 2021
| 9 min read
2019 and 2020 were worlds apart. Our entire ways of working, living, socializing, and learning were changed almost overnight. Over the last 18 months, technical teams have had to double down on all their digital efforts to help their customers adapt to the new normal. At the same time, teams were responsible for more unplanned work than ever as incidents steadily rose.
For the first time, we’ve created the State of Digital Operations Report which is based on PagerDuty platform data. This report shows the disparity between the work technical teams faced in 2019 versus 2020. We saw changes in the number of critical incidents, common metrics such as MTTR and MTTA, how the added pressure affected burnout, attrition, and more.
In the latest installment of this blog series, we will walk through some of these findings and share 10 questions teams can ask themselves to improve their incident response.
What changed?
According to our platform data, critical incidents increased 19% YoY from 2019 to 2020. We view critical incidents as those from high-urgency services, not auto-resolved within five
minutes, but acknowledged within four hours and resolved within 24 hours.
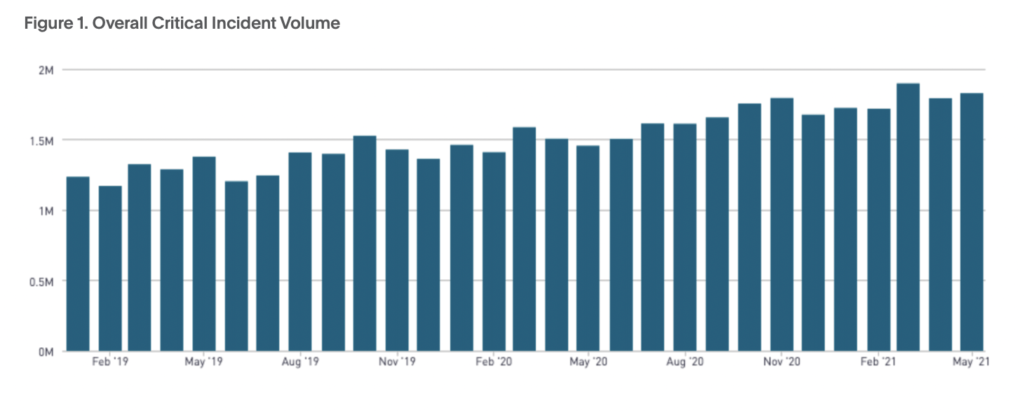
Even as critical incidents increased, MTTA (mean time to acknowledge) and MTTR (mean time to resolution) have decreased. MTTx metrics don’t provide the whole picture of your incident response process or your operational maturity. But, they can give you insights into performance overall, and can help you benchmark areas of strength as well as areas of improvement.
We found that, the longer a team was using PagerDuty, the lower the MTTA and MTTR became. We see this improved MTTA as a sign of increased accountability. As the MTTA improves, so does the ack%, or the amount of alerts acknowledged by the on-call engineer.
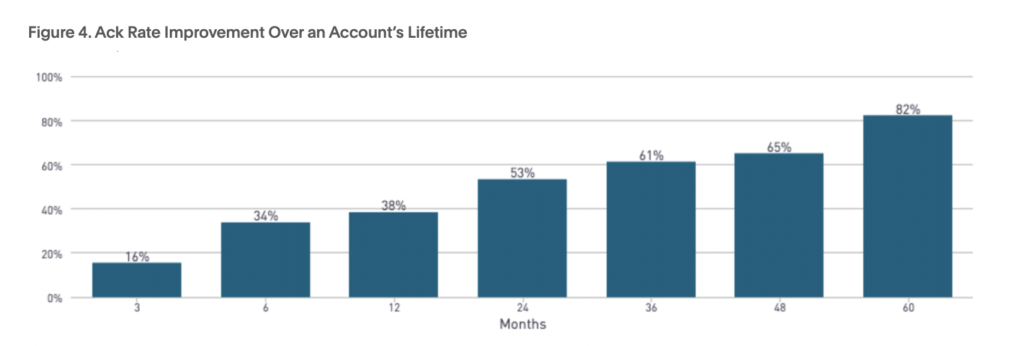
Yet, even though MTTA and MTTR have decreased, time spent resolving incidents is still up. Teams have to work smarter, not harder. To do this, they can pinpoint parts of the incident response lifecycle for optimization.
10 questions to ask about your incident response lifecycle
The incident response lifecycle is a process that follows a failure in your system. It begins with detecting the failure, then moves on to preventing customer impact, mobilizing a team to respond, diagnosing what’s happening, resolving the issue, and learning from the experience. At each stage, there are opportunities to finetune your operations to resolve incidents faster and with less cognitive toil.
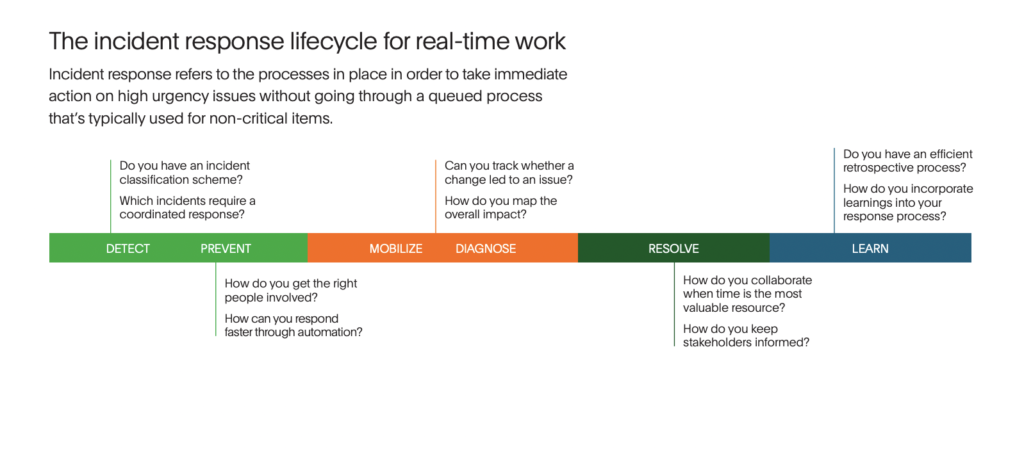
Detect: This stage can happen in a few ways. The best case scenario is that your monitoring alerts you that there’s an abnormality that requires your attention. Worst case scenario is that detection begins with a customer having to tell you there’s a problem. Either way, you can have a speedier response by answering these questions ahead of time:
- What is our organization’s incident classification scheme? Some teams like to use severities. Others call them priorities. Whatever nomenclature you use, make sure that everyone on the team understands how to classify an incident. What makes it a Sev1 opposed to a Sev3? Understanding this ahead of time helps you call the shots better when an incident actually happens.
- Which incidents require coordinated response? Now that you’ve determined what these severities look like, you should make a plan for the type of people who need to be looped in for each. For instance, a Sev3 might be perfectly fine for a single on-call engineer to handle. A Sev1, however, might need all hands on deck, including management. Planning this out helps you avoid indecision during mission-critical moments.
Prevent customer impact: At this stage, you’re trying to limit the amount of customer impact possible. You do this by getting the right people involved as soon as possible and looking for opportunities to automate. This can cut minutes off your response times. Ask yourself these questions to understand how you can improve:
- How do you get the right people involved? Above, we noted that determining the right types of people to loop in for each severity is key. Here, we’re thinking about how to get the actual people involved in the incident early. One way to do this is with full-service ownership and a detailed on-call rotation. When you have all your services mapped and a team assigned to each, it’s easier to know which team is responsible for resolving the incident. Further, with detailed on-call scheduling, the alert for the service in question should route to the precise engineer who will begin the response process.
- How can you respond faster through automation? Nirvana here is being able to auto-remediate incidents without human intervention. While you may be able to do this for the most common incidents that you experience, it’s more likely that you’ll adopt an approach similar to PagerDuty customer Parsons, which automates small tasks and then strings together more complex sequences over time.
Diagnose: This stage is about understanding the problem you’re up against, including potential causes and dependent services impacted. As you work towards pinpointing the cause of the incident, you can look into changes that might have impacted the services you’re responsible for, and how the entire ecosystem is affected. The sooner you have a grasp of what’s happening, the faster you can fix it. Think about questions like:
- Can you track whether a change led to an issue? The most common cause of an incident is a change in the code base. If you have a change events management tool, you can look at recent deployments and find a possible culprit faster. While this can’t usually give you a 100% affirmative solution, it can provide you with a direction to move in. Make sure you’re tracking changes and that all on-call engineers have this information available for the services they respond to.
- How do you map the overall impact? It’s important to understand how your service affects others, both technical and business. To do this, you should map what dependencies your service has, and what services yours is dependent on. A service graph can help you visualize this. Beyond the technical aspects, consider how your service impacts the business and map your technology functions to the business level. To understand how to handle business incidents with this integrated approach, check out this Ops Guide.
Resolve: This is the part of the process that most people think of when they picture incident response. A team of talented individuals who believe they know what the issue is, and how to fix it. At this point, your SMEs (however many are involved, depending on the severity) are working towards restoring service to customers. The quicker this is complete, the less business impact this incident has. But before you’re in the weeds, it’s important to outline these two things.
- How do you collaborate when time is the most valuable resource? Make sure ahead of incidents that you understand what roles each severity of incident requires, and what the responsibility of those roles are. For instance, the incident commander might only be used in incidents Sev2 and above. This person will take the helm of the response process. The scribe, meanwhile, will document all important discoveries during this time. PagerDuty roles and responsibilities are detailed here for further reading.
- How do you keep stakeholders informed? How teams communicate internally is important, but you also need to consider how to communicate to other line-of-business stakeholders like customer success, sales, PR, and senior leadership. Make sure your communication plan is outlined according to severity. For more information on how to communicate with stakeholders, you can review this guide.
Learn: After an incident concludes, it’s too late to speed up the resolution time for this failure. However, the learnings from each incident can help you resolve a similar incident better in the future. Try to make time to review all critical incidents and conduct a thorough postmortem. To analyze how your team is learning, you can ask these questions:
- Do you have an efficient retrospective process? When conducting a retrospective, you should come prepared ahead of time and ready to discuss the incident. You’ll need to create a timeline, document impact, analyze the incident, create action items, write external messaging, and have a thorough discussion of what happened. Most importantly, you’ll need to keep this process blameless. It’s key to approach it from a learning perspective rather than pointing fingers. To learn more about postmortems, you can take a look at this guide.
- How do you incorporate learnings into your response process? After a good postmortem, you’ll have learned something new about your system. You can prioritize action items and fix bugs to make the affected service more reliable in the future. Additionally, you can make improvements to your response process. This helps you be more efficient and prepared. Look for any communication breakdowns, opportunities for automation, or ways your documentation could be improved.
These 10 questions can help your team better understand where you sit in terms of your incident response maturity. As you make incremental investments to improve processes, you’ll find that you’re better able to handle the ever-increasing amount of incidents.
What’s next?
Headcount isn’t growing to meet the number of incidents teams are facing. And, with the Great Resignation at hand, it’s important to work efficiently until new teammates are trained. While increasing resourcing is something that should be addressed to help teams balance the workload better, you can also improve the ways you detect incidents, prevent customer impact, diagnose and resolve the issue, and learn from failure.
PagerDuty can help your team with these initiatives. To see for yourself, sign up for your 14-day free trial. Or, if you’re curious about more of our platform data findings, you can read the entire State of Digital Operations Report.

