- PagerDuty /
- Blog /
- Best Practices & Insights /
- Best 10 DevOps Tools for 2021
Blog
Best 10 DevOps Tools for 2021
by Priya Sony
November 19, 2020
| 8 min read
Gaining operational maturity isn’t something that happens overnight after implementing new tools. At its core, it’s a concerted effort in shifting culture so that people can break down communication silos to ship better software and implement more transparent processes. And while tools alone don’t lead this transformation, they provide a crucial stepping stone to applying automation and developmental structure that improves speed, increases accuracy, and boosts cross-team collaboration.
There is a wide selection of DevOps tools available in the market, so it could be confusing and intimidating when evaluating not only which are best for you, but also when and how to use each tool to get the most out of it. There is no one-size-fits-all solution out there, and frankly, if there was, it’d likely be over-complicated and far too complex to use. DevOps tools help ensure automation, transparency, and collaboration are at the forefront of your developmental processes.
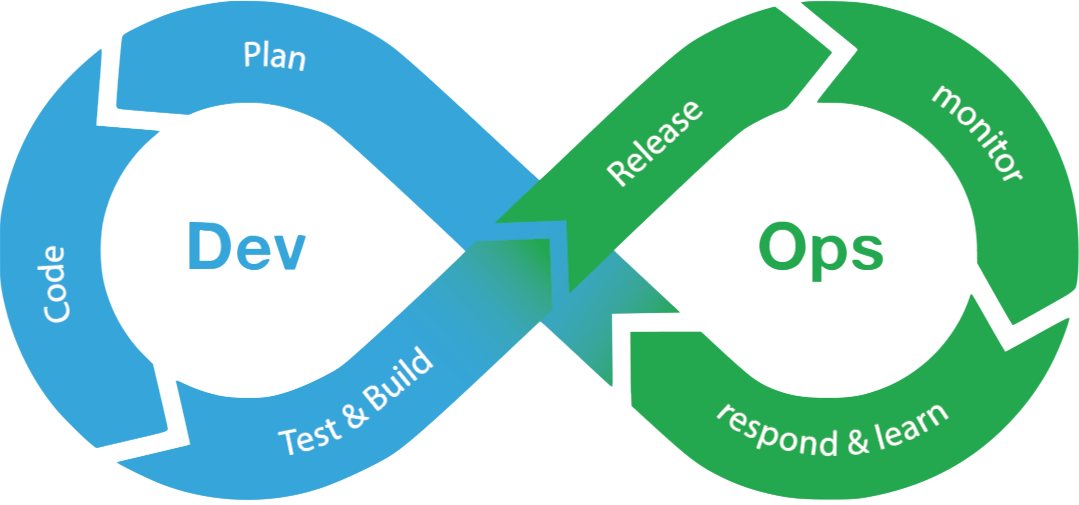
In our experience, here are the 10 best DevOps tools for your 2021 toolkit in no particular order.
Best DevOps Tool for Planning: ActiveCollab
As your team is sharing ideas and planning at the start of each sprint, take into account feedback from the previous sprint’s retrospective so the team and your services are continuously improving. Tools can help you centralize learnings and ideas into a plan.
ActiveCollab is a Project Management tool that makes it easy to track and control workflow processes. You can easily create tasks with advanced task management that offers multiple task views and recurring tasks; set deadlines and task dependencies; and ActiveCollab has one of the best and invoice and expense tracking systems built in – no need for a separate billing tool. Plus, it’s used by companies like Apple, Microsoft, and NASA to name a few.
Honorable Mentions: Pivotal Tracker, VersionOne, Jira, Trello, StoriesOnBoard
Best DevOps Tool for Coding: Github
After you’ve written some code, there’s a few things that need to happen before getting it into staging. Get it code reviewed and approved, merge it into the master branch in a version control repository, and run any local tests as needed.
GitHub is one of the most popular and essential tools in a DevOps toolkit. It’s used by over 50 million developers around the world, including major tech companies like Google, AirBnB, and Spotify. It’s great for both open source and business applications, allows you to host and review your code easily, and is great for managing individual projects.
Honorable Mentions: Bitbucket, Gerrit, GitLab
Best DevOps Tool for Testing & Building: Jenkins
Now it’s time to automate the execution of tasks related to building, testing, and releasing code. There are a number of great open source and paid tools that do useful things once the tests are complete, like automatically picking up changes to the master and pulling down dependencies from a repository to build new packages. Our pick is Jenkins.
Jenkins helps to streamline the building, deploying, and automation of your projects. It allows you to go big or small with its extensible automation server that works great as both a simple CI (continuous integration) server or a hub for continuous project delivery. You can write and deploy new code faster, allowing you to easily QA each step of the build process. Plus, it offers a huge library of plugins, allowing you to integrate it with many of the other DevOps tools in your toolkit.
Honorable Mentions: GoCD, Maven, CruiseControl, TravisCI, CircleCI
Best DevOps Tool for Containers & Schedulers: Docker
Containers standardize how you package your application, improving storage capacity and flexibility, and making it easier to make changes faster.
Docker is our favorite tool for containers and schedulers, and it’s no surprise that it has been the top container platform since launching seven years ago in 2013. In fact, Docker played a big role in popularizing containerization. It allows you to stop using outdated tools like VirtualBox, and takes away the headache of dependency management. It also integrates with automation tools like Jenkins and Bamboo.
Honorable Mentions: Kubernetes, Mesos, Nomad
Best DevOps Tool for Configuration Management: Chef
With configuration management, you can track changes to your infrastructure and maintain a single source of system configuration.
Chef is a powerful configuration management tool used by major companies like Facebook and Nordstrom. Chef makes it easy to version control and make replicas of images — i.e. anything you can take a snapshot of like a system, cloud instance, or container. It’s great for deploying and managing your applications and servers in-house as well as on the cloud.
Honorable Mentions: Ansible, Puppet, SaltStack
Best DevOps Tool for Release/Deployment Automation: Bamboo
Release automation tools enable you to automatically deploy to production. They should include capabilities such as automated rollbacks, copying artifacts to the host before starting the deployment, and especially if you’re a larger organization, agentless architecture to easily install agents and configure firewalls at scale to your server instances.
Bamboo is our favorite DevOps tool for release automation because of how efficiently it allows you to link your builds, test, and releases into a single and easy to manage workflow. Why we love Bamboo for release automation is its incredible support for continuous delivery.
Honorable Mentions: Jenkins, Puppet
Best DevOps Tool for Deployment & Server Monitoring: Datadog
It can be really helpful to have release dashboards and monitors set up that help you visualize high-level release progress and status of requirements. It’s also key to understand whether services are healthy and if there are any anomalies before, during, and after a deploy. Server monitoring gives you an infrastructure-level view. A lot of teams also use log aggregation to drill down into specific issues.
Datadog makes it easy to monitor servers and deployment using infrastructure metrics, traces, and logs right in your dashboard. The great part is viewing your data from any scale. Datadog allows you to visualize your entire infrastructure and applications from a bird’s eye view, or zoom in for a detailed look at any one of your hosts or containers.
Honorable Mentions: AWS Cloudwatch, Splunk, Nagios, Pingdom, Solarwinds, Sensu, Elastic Stack, PagerDuty
Best DevOps Tool for Monitoring Application Performance: New Relic
Application performance monitoring provides code-level visibility of the performance and availability of applications and business services, such as your website. This makes it easy to quickly understand performance metrics and meet service SLA’s.
New Relic allows you to easily monitor the performance of your applications, including Php, Ruby, Java, and NodeJS. The tool pulls all of your telemetry data into a single location to provide you with full-stack monitoring, as well as AI-driven insights to help improve your service reliability. It’s, as they say, “observability made simple.”
Honorable Mentions: Dynatrace, AppDynamics
Best DevOps Tool for Incident Response: PagerDuty
Monitoring tools provide a lot of rich data, but that data isn’t useful if it isn’t routed to the right people who can take the right actions on an issue in real time. To minimize downtime, people must be notified with the right information when issues are detected, have well-defined processes around triage and prioritization, and be enabled to engage in efficient collaboration and resolution.
PagerDuty helps you get the most out of your on-call operations by orchestrating the right responses for every incident. It provides on-call alerting along with on -call rotations and scheduling while allowing you to automate work across teams, execute detailed playbooks, and accelerate resolutions. PagerDuty helps you to resolve critical incidents faster while also preventing future occurrences.
Honorable Mentions: Slack, Conferencing tools
Best DevOps Tool for Learning: PagerDuty Postmortems
When wartime is over, incidents provide a crucial learning opportunity to understand how to improve processes and systems to be more resilient. In accordance with the CAMS pillars of DevOps (Culture, Automation, Measurement, Sharing), it’s important to understand incident response and system performance metrics, and facilitate open dialogue to share successes and failures towards the goal of continuous improvement.
PagerDuty Postmortems is a great resource for on-call practitioners who want to iteratively learn from incidents affecting their team and for managers who want to cultivate a culture of learning in their organization. It clearly outlines the who, what, and why of postmortems, and provides detailed instructions for writing them and effectively integrating a successful post mortem process into your company culture.
Honorable Mentions: Looker, Pendo, SurveyMonkey
Build the Right DevOps Toolkit for Your Company
Again, simply investing in tools will not get you from a monolithic to a microservices architecture, or magically result in teams that can perform self-service deployments many times a day. But by bolstering a culture shift with the right tools and processes, you’ll be well on your way to optimizing and continuously improving software delivery and enabling seamless collaboration and trust between everyone responsible for it.
With that, we wish you success in exploring and finding the right tools for you! And check out these resources if you’re interested in learning more about which tools we use internally to maximize inclusivity, and how to accelerate DevOps best practices.